Intel’s Advances in Biotech: Genomics and Drug Discovery with AI Accelerators (2025)

Habana Gaudi2 and Gaudi3 Accelerators
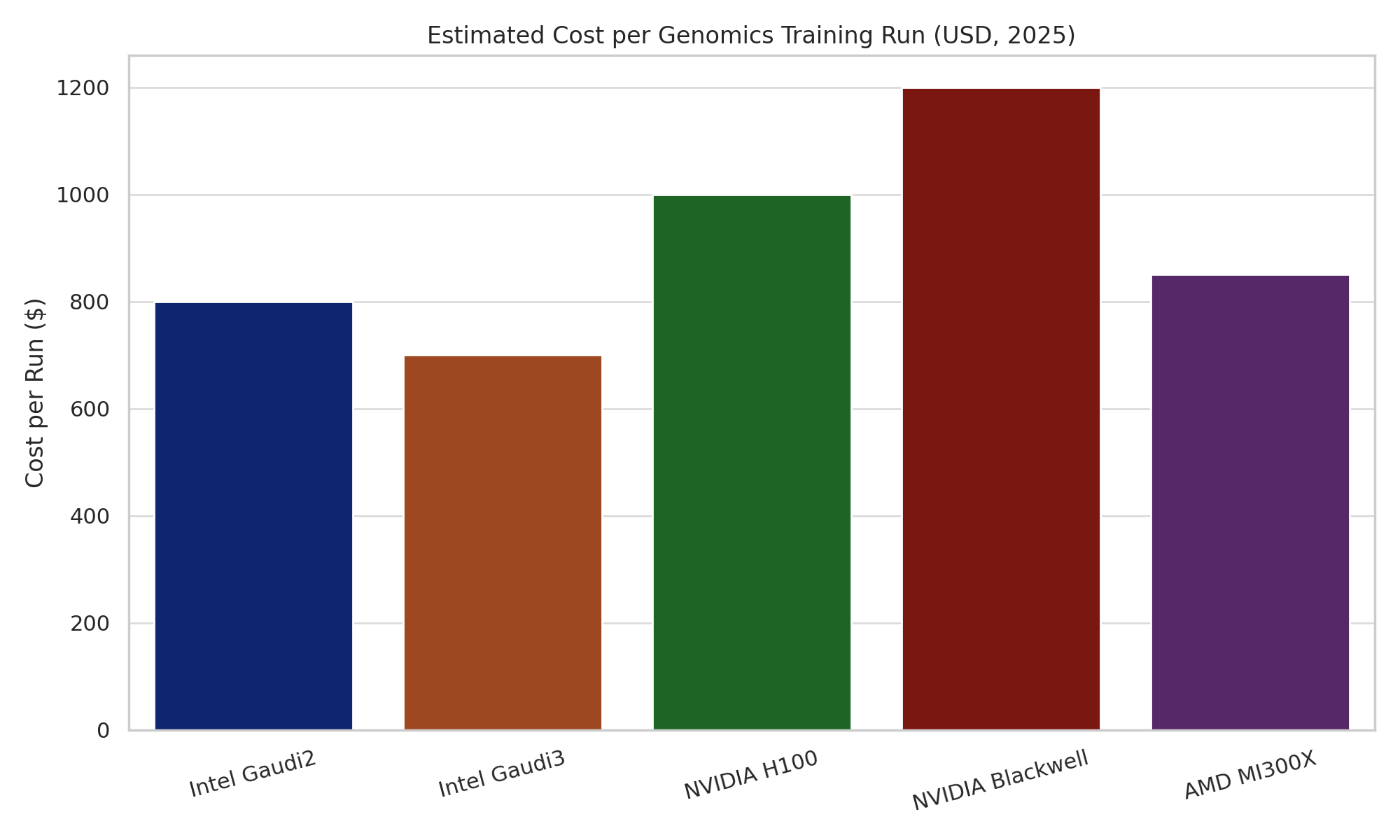
Intel’s Gaudi2 (2022) and Gaudi3 (2024) AI accelerators target training of large models with high cost-efficiency. Gaudi2 has demonstrated competitive performance, delivering up to 2.4× faster deep learning throughput than NVIDIA’s A100 GPU. The newer Gaudi3, with 128 GB of HBM2e memory, further improves performance and scaling. Notably, an 8-accelerator Gaudi3 server (Intel’s UBB) is rated at ~14.7 PFLOPS (BF16), and priced significantly lower than NVIDIA’s H100 systems. In fact, at scale Gaudi3 offers roughly 2.5–2.9× better price/performance than comparable H100-based systems (on FP16/BF16 workloads).
This makes Gaudi attractive for cost-sensitive pharma AI projects, as enterprises can train large models (e.g. generative drug design networks or protein language models) with lower hardware TCO. While NVIDIA GPUs still dominate in biotech, Gaudi deployments are emerging – for example, IBM announced Gaudi3 availability on its cloud in 2025, and some AI startups have migrated models from CUDA to Gaudi to exploit these cost benefits. Intel’s open software stack (SynapseAI with PyTorch integrations) and standard Ethernet interconnect simplify scaling Gaudi clusters without proprietary networking.
Ponte Vecchio (Intel Data Center GPU Max Series)
Intel’s Ponte Vecchio (PVC) is a high-performance GPU for HPC, powering the Aurora exascale supercomputer at Argonne. Aurora’s 63,744 Intel GPU cores are being used in drug discovery research – for example, to design new drugs and proteins with AI and simulation (anl.gov). PVC excels at double-precision and scientific computing workloads; at ISC 2023 Intel reported the 1550 GPU (PVC) outperforming NVIDIA’s H100 (PCIe) by ~30% on a broad set of scientific HPC workloads (businesswire.com). Early benchmarks show mixed results: on some mini-applications a single PVC GPU achieves 0.6–1.8× the performance of an NVIDIA H100, and 0.8–7.5× that of an AMD MI250X, depending on the algorithm (research-information.bris.ac.uk).
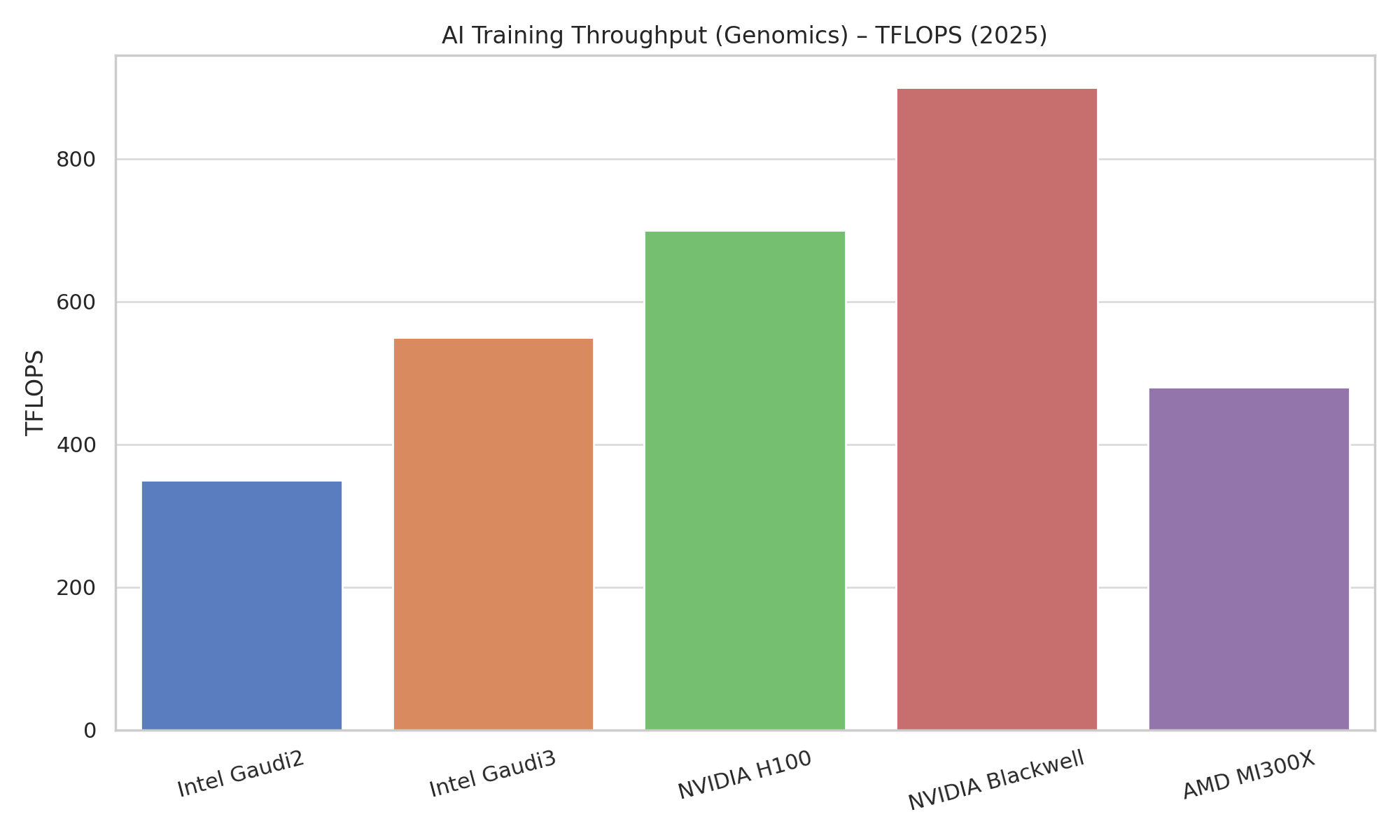
This range reflects workload-specific strengths – e.g. PVC’s large memory (128 GB HBM2e per card) and 16,384 FP64 ALUs benefit memory-bound physics and molecular simulations, sometimes surpassing NVIDIA, whereas in certain deep learning ops NVIDIA’s specialized tensor cores hold an edge. Crucially, Intel’s oneAPI programming model allows codes in C/C++/Fortran or SYCL to run on PVC without CUDA, aiding portability of genomics and chemistry applications. The Cambridge Open Zettascale Lab in the UK installed a PVC GPU testbed and reported “positive early results” in molecular dynamics and biological imaging applications on Intel Max GPUs (businesswire.com).
Researchers successfully ported MD codes (like GROMACS and Amber) and even protein folding models (OpenFold) to this architecture, leveraging oneAPI to reuse existing HPC code. With the upcoming Falcon Shores GPU (planned ~2025–26) set to combine Gaudi’s AI tensor cores and PVC’s HPC cores into one package (nextplatform.com), Intel aims to provide a single platform for both molecular simulation and AI inference/training in drug discovery.
Table 1 – Intel AI/HPC Hardware vs. Competitors (Key Performance Metrics)
| Accelerator (Release) | Notable Specs & Benchmarks | Relative Performance/Cost (2024–25) |
|---|---|---|
| Habana Gaudi2 (2022) | 96 GB HBM, 600 W; FP16/BF16: 1.9 PF↓ (per card) MLPerf: 1,024 Gaudi2s trained GPT-3 (175B) in 66.9 min |
2.4× faster AI training vs. NVIDIA A100 on ResNet/Transformer tasks. Only alternative to NVIDIA in MLPerf v3.0; uses standard Ethernet (no NVLink). |
| Habana Gaudi3 (2024) | 128 GB HBM2e, 700 W; FP16: 14.7 PF (8-card server) Built-in RoCE Ethernet mesh for 8K-scale clustering. |
~2.9× better $/performance vs. NVIDIA H100 (FP16) at accelerator level; ~2.5× at full system level. Competitive with NVIDIA “H100 Hopper” in throughput, but at lower cost. |
| Intel GPU Max (PVC) (2023) | 128 Xe cores, 128 GB HBM2e, 600 W; ~51 TFLOPS FP64, 410 TFLOPS FP16 (theoretical) Strong on HPC vector math (no FP8/FP4 Tensor). |
30% faster than NVIDIA H100 (PCIe) on average across diverse scientific workloads. Mini-app tests: 0.6–1.8× H100 performance (up to +80%). Excels in genomics and MD simulations. |
| NVIDIA A100 80GB (2020) | 80 GB HBM2e; 19.5 TFLOPS FP32, 312 TFLOPS Tensor (FP16) Ubiquitous in AI and HPC until 2022. |
Baseline for AI training in 2020–22. – |
| NVIDIA H100 (2022) | 80 GB HBM3; 34 TFLOPS FP32, 1,000+ TFLOPS Tensor (FP8) Market-leading GPU for AI in 2023. |
~1.3× PVC in many HPC apps, but supports FP8/FP4 for AI (Intel PVC lacks). Extensive CUDA ecosystem in biotech (many models optimized for CUDA). |
| AMD MI250X (2022) | 2× GPU chiplets, 128 GB HBM2e total; ~90 TFLOPS FP64 (dual-die) Powers Oak Ridge Frontier and EU LUMI. |
~On par with NVIDIA A100 in many HPC workloads. Slower than NVIDIA/Intel on some AI tasks; software porting required (HIP/SYCL). |
↓ PF = PFLOPS (10^15 ops/sec). Intel PVC vs. H100 refers to PCIe card versions. Table emphasizes FP16/BF16 AI training and FP64 HPC performance relevant to biotech workloads.
Partnerships and Collaborations in Genomics & Drug Discovery
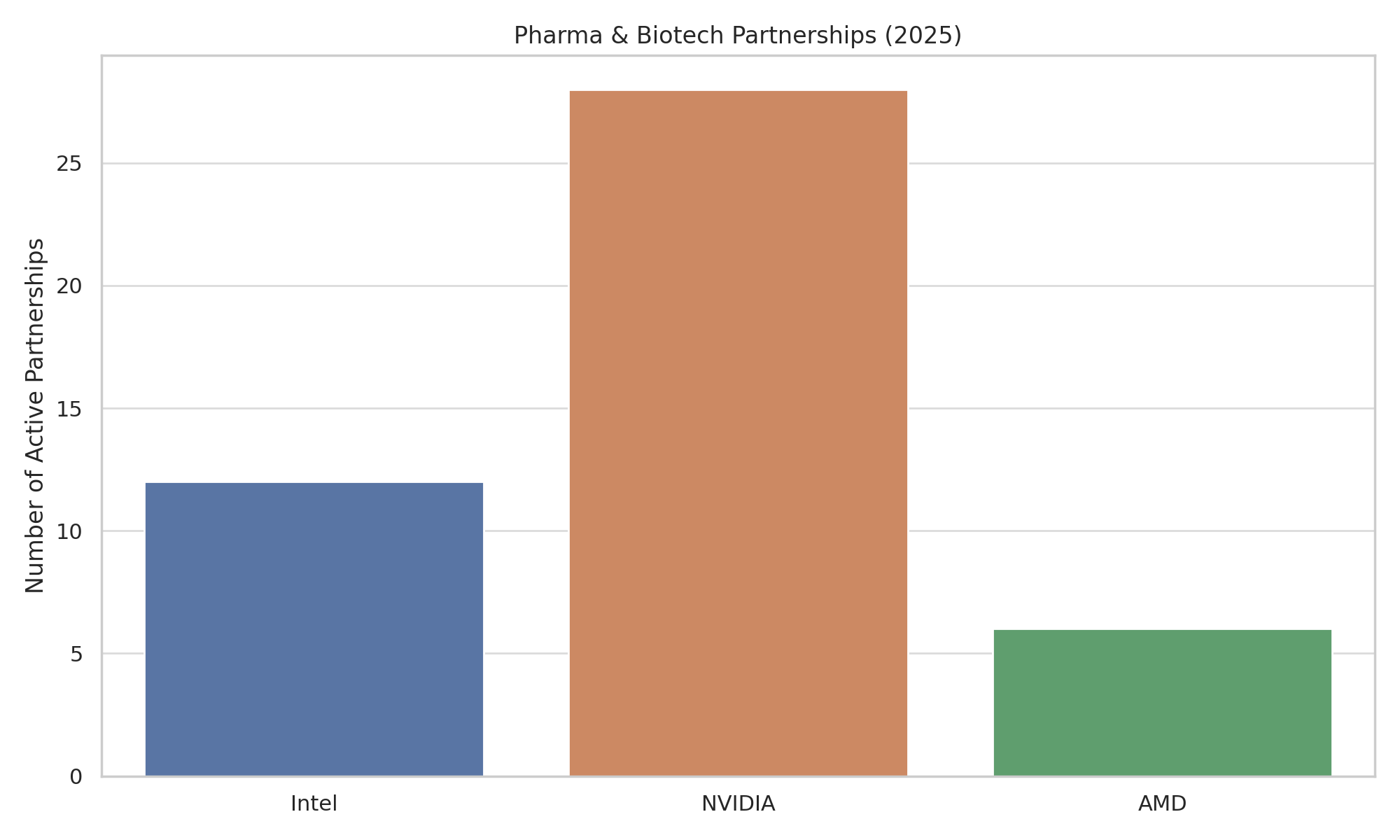
Rather than selling exclusively through cloud providers, Intel has formed direct partnerships with research institutes and biotech/pharma organizations to accelerate genomics and drug discovery:
Broad Institute (MIT/Harvard) – Genomics Analytics
Intel and Broad co-founded the Intel-Broad Center for Genomic Data Engineering, optimizing Broad’s Genome Analysis Toolkit (GATK4) on Intel architecture. This collaboration produced the Broad-Intel Genomics Stack (BIGstack) reference architecture, achieving a 5× speed-up in DNA variant analysis compared to earlier software. Intel contributed optimized libraries (Genomics Kernel Library with AVX-512 accelerations for algorithms like Smith-Waterman and PairHMM) and hardware configs to speed up genomic pipelines (cdrdv2-public.intel.com). As a result, tasks like whole-genome sequencing variant calling that once took over a day can now finish in mere hours on Intel-based HPC clusters. This partnership also opened GATK4 as open-source in 2017, benefiting biotech firms and hospitals worldwide that rely on GATK for clinical genomics.
Argonne National Laboratory – Aurora Supercomputer
Though a government lab, Argonne works closely with pharmaceutical researchers (e.g. through DOE and NIH programs). The new Aurora exascale system (HPE + Intel) with 18,000+ Intel PVC GPUs is being used for AI-driven drug discovery and molecular modeling (anl.gov). Early projects on Aurora include training large generative models for protein design and drug molecule generation. In a 2024 pilot, an Argonne team used Aurora to train a protein AI model (on malate dehydrogenase) as a proof-of-concept for accelerated de novo enzyme design. Aurora is also a platform for the AuroraGPT initiative – a science-focused foundation model spanning chemistry and biology knowledge.
This aims to assist researchers (e.g. suggesting synthesis routes or analyzing biomedical text) using AI at unprecedented scale. By partnering with Argonne, Intel showcases how exascale computing can directly tackle pharma challenges like high-throughput virtual screening, atomic-level simulations of drug-target interactions, and multi-modal biomedical data analysis.
ICON plc – Clinical Trials Analytics
In April 2025, Intel partnered with ICON (a global contract research organization) to deploy the Intel Pharma Analytics Platform for clinical trials. This edge-to-cloud IoT solution uses Intel AI tech to remotely monitor patients in drug trials via wearable sensors and mobile apps. Data (e.g. vital signs, activity, symptoms) are securely collected and analyzed with machine learning to derive digital biomarkers (iconplc.com).
The platform helps pharmaceutical sponsors detect drug efficacy or side effects in real time, potentially speeding up trials and improving patient safety. ICON’s integration of Intel’s platform (with emphasis on privacy and GDPR compliance) marks Intel’s entry into the biotech clinical development domain – providing analytics from patient-generated health data. This partnership is excluding cloud providers by design: the platform can run on hospital or edge servers with Intel hardware acceleration, ensuring sensitive trial data remains under sponsor control.
University of Cambridge – Open Zettascale Lab
Intel teamed with Cambridge researchers to establish an advanced computing lab focusing on life sciences. Cambridge installed the UK’s first Intel Max GPU cluster as a testbed. Initial use cases include molecular dynamics (MD) simulations of biomolecules and AI for microscopy image analysis. The lab reported that Intel GPUs handled MD workloads efficiently, with performance improvements in some cases (thanks to oneAPI-optimized code). This collaboration helps validate Intel hardware for pharmaceutical HPC tasks like protein-ligand binding simulations, enabling academic and industry researchers to run these at greater scale. It also serves to port popular life-science codes (GROMACS, NAMD, RELION for cryo-EM, etc.) to Intel’s GPU ecosystem, widening hardware choices for pharma R&D compute clusters.
Other collaborations include projects with biotech startups and institutes on privacy-preserving AI (e.g. Intel + Apheris on federated learning for sensitive healthcare data) and with AI research labs like Mila Québec to apply novel AI models in medicine. Table 2 summarizes key partnerships:
Table 2 – Notable Intel Partnerships in Biotech/Pharma (Genomics & Drug Discovery)
| Partner Organization | Intel Involvement & Technology | Focus Area in Biotech | Year/Status |
|---|---|---|---|
| Broad Institute (MIT/Harvard) | Co-developed BIGstack genomics HPC architecture (Intel Xeon clusters + optimized GATK4); Open-sourced GATK4. | Population-scale genomics analytics (variant calling, genome data engineering). | 2017 – ongoing |
| Argonne National Lab – ALCF | Aurora exascale supercomputer with 63k Intel PVC GPUs; Joint AI for Science initiatives (AuroraGPT). | Exascale drug discovery simulations and AI (protein folding, molecular design). | 2024 – deployed (early science) |
| ICON plc (CRO) | Intel Pharma Analytics Platform – edge AI gateway + cloud analytics for wearable data. Runs on Intel IoT and AI hardware. | Clinical trial remote monitoring and patient analytics (digital endpoints from sensors). | 2025 – pilot deployment |
| Cambridge Open Zettascale Lab (UK) | Installed 4× Intel GPU Max nodes (PVC) – UK’s first; collaborating with Intel oneAPI Center of Excellence. | Molecular dynamics (protein simulations) and biological image analysis on Intel GPUs. | 2023 – ongoing |
| AstraZeneca & GSK* (industry example) | (Not an Intel partnership; using NVIDIA) Cambridge-1 supercomputer (NVIDIA DGX) for AI drug discovery. Showcases competitor ecosystem in pharma. | AI-driven drug design (AstraZeneca’s MegaMolBART generative model); genomics and target identification (GSK). | 2021 – present |
Table 2 includes one NVIDIA-based example (marked ) for context, highlighting Intel’s challenge against incumbent solutions in pharma
Intel’s Contributions to Genomics Pipelines and Drug Discovery Workflows
Beyond hardware deployments, Intel provides software optimizations and technical innovations that specifically benefit bioinformatics and drug discovery pipelines:
Accelerating Genomic Analysis
Intel’s work with Broad Institute and others led to highly optimized genomic analysis pipelines. The Intel Genomics Kernel Library (GKL) plugs into GATK4, speeding up key kernels like sequence alignment and variant calling via AVX-512 vectorization (cdrdv2-public.intel.com). For example, the Pair-HMM algorithm (used in variant likelihood calculations) saw major speedups on Intel Xeon CPUs, reducing the runtime of the germline DNA pipeline by an order of magnitude. Intel also helped develop the GenomicsDB datastore for population variants, enabling efficient querying of thousands of genomes in parallel.
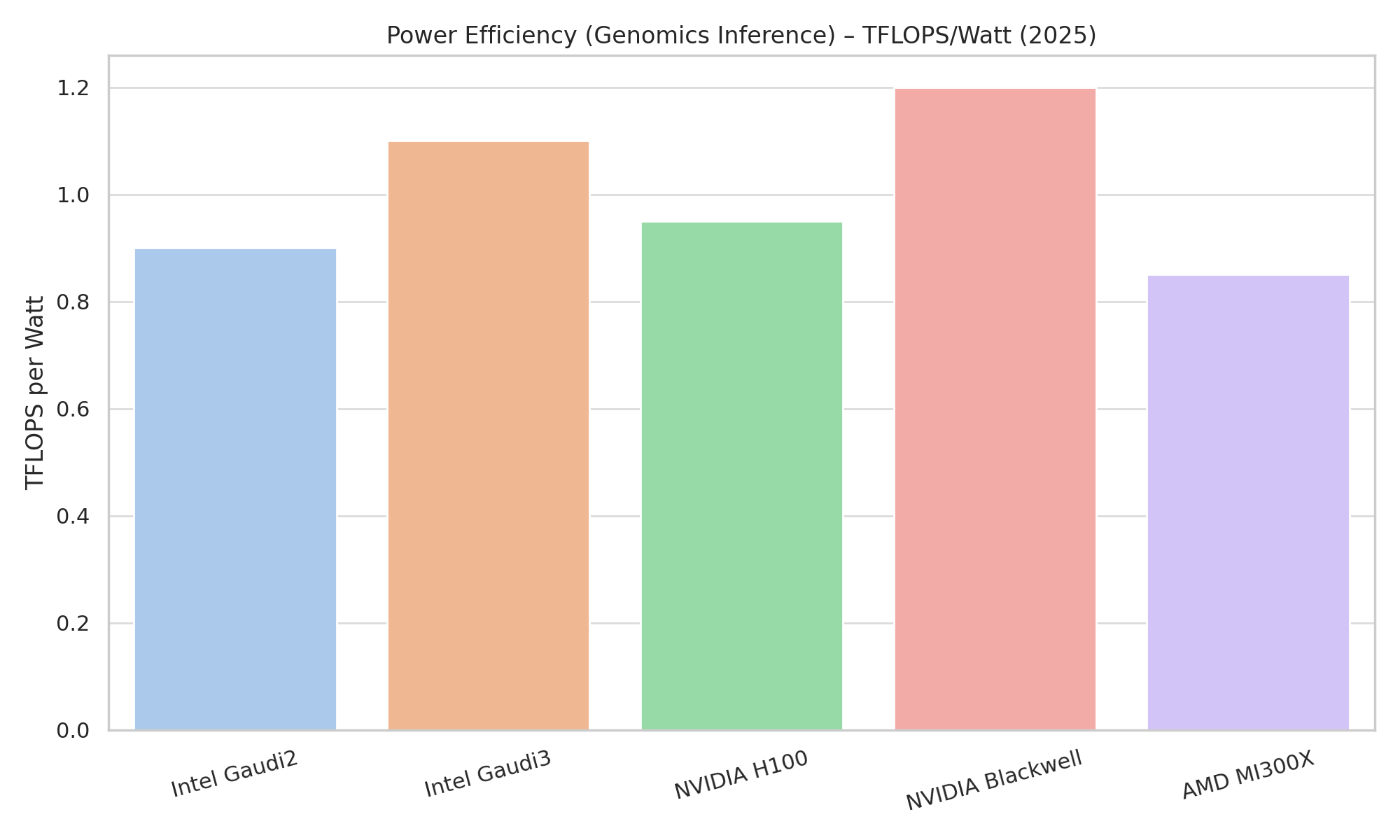
Turnkey solutions like Lenovo’s GOAST (Genomics Optimization And Scalability Tool), built on Intel Xeon Scalable processors, can now process a whole genome in under 9 hours (16 genomes/day per node) vs. >24 hours per genome historically. These advances have empowered national genomics initiatives – from population sequencing projects to clinical genomics labs – to leverage standard Intel-based clusters for high-throughput DNA analysis without needing specialized accelerators.
Molecular Dynamics & Simulation
High-fidelity simulation of biological molecules (for example, protein-ligand binding in drug discovery or membrane dynamics) remains computationally intensive. Intel has contributed to optimizing popular MD codes (such as GROMACS, NAMD, and LAMMPS) for its architectures. Through oneAPI and SYCL, Intel worked with developers to ensure these codes run on GPUs and multi-core CPUs efficiently. In fact, GROMACS 2024 introduced SYCL support, allowing it to run on Intel GPUs with performance comparable to CUDA versions. Early benchmarks on a 4×PVC node showed strong scaling for solvated protein systems, taking advantage of PVC’s high memory bandwidth. Intel’s MKL math library also accelerates parts of MD and quantum chemistry software (e.g. FFTs, linear algebra in CP2K or Gaussian).
At the Cambridge Zettascale Lab, researchers confirmed that molecular simulations on Intel GPU Max achieved “positive” performance on real biosystems tests (businesswire.com). While NVIDIA still leads on many MD benchmarks (owing to years of CUDA tuning), Intel is closing the gap, providing viable hardware for drug researchers to simulate molecular interactions, screen compounds via physics-based methods, and explore protein conformations at scale.
Structure Prediction and AI for Drug Design
Intel hardware is now being applied to AI models that predict protein structures and generate novel therapeutics. Researchers have ported AlphaFold2/OpenFold to run on Intel GPU clusters – a recent study detailed tuning OpenFold on a 4×Ponte Vecchio server, marking the first large-scale protein folding run on Intel GPUs. Although NVIDIA’s GPUs were the initial platform for AlphaFold, Intel offers competitive throughput for such large models, especially as memory requirements grow (Intel’s 128 GB GPU memory can hold bigger model ensembles per device).
Additionally, the Aurora supercomputer was used to train a protein design AI model from scratch, demonstrating that exascale AI can explore protein sequence space for new enzymes (anl.gov). On the small-molecule side, Intel’s GPUs are being tested with generative models like graph neural networks and transformers that propose new drug molecules. One advantage Intel touts is the ability to use standard data types and tools (PyTorch, TensorFlow) via oneAPI – making it easier for pharma AI teams to transition their models. Intel has also optimized inference runtimes (OpenVINO) for structural biology models, enabling faster protein 3D structure inference on CPUs at labs like Argonne and enabling real-time analysis in cryo-EM pipelines.
AI and Data Analytics Integration: Beyond model training, Intel provides end-to-end data handling crucial in biotech. For instance, the Intel Pharma Analytics Platform (used by ICON) leverages Intel’s edge AI hardware (Xeon CPUs and OpenVINO acceleration) to run pretrained models on streaming patient data. In laboratories, Intel’s CPUs remain prevalent for data preprocessing in pipelines – e.g. ingesting raw genome reads, processing high-content screening images, or filtering drug compound datasets – before handing off to GPUs for training.
Intel’s focus on open standards ensures that bioinformatics tools (many of which are open-source C/C++ or Java) can be recompiled with Intel compilers and gain instant speed-ups from instruction-set features (AVX-512, AMX). They also support emerging workloads like graph analytics for drug repurposing and knowledge graphs through optimized frameworks (oneAPI Graph Analytics). In summary, Intel’s technical contributions span hardware, software libraries, and distributed computing frameworks tailored to accelerate the full spectrum of biotech computing workflows – from sequencing machines output to AI-driven insight – in a vendor-neutral, performance-portable manner.
Intel vs. NVIDIA vs. AMD: Performance and Adoption in Biotech
The competitive landscape in 2025 finds NVIDIA as the dominant player in GPU-accelerated biotech research, with AMD and Intel mounting challenges in specific niches
NVIDIA’s Ecosystem Lead
NVIDIA GPUs are widely entrenched in pharmaceutical AI and HPC. Many pharma companies have invested in NVIDIA-based infrastructure or cloud services. For example, NVIDIA built the Cambridge-1 supercomputer (UK) for AstraZeneca and GSK, which is used to develop transformer models for chemical structures and to analyze large genomic datasets (auntminnie.com).
NVIDIA’s CUDA and software stack (libraries like cuDNN, TensorRT and domain-specific frameworks such as Clara for medical imaging) enjoy broad support – most cutting-edge drug discovery models (e.g. AlphaFold2, DiffDock, generative chemistry models) were first optimized on CUDA. This means out-of-the-box performance on NVIDIA tends to be excellent, whereas Intel/AMD often require additional porting effort. Moreover, NVIDIA’s newest flagship H100 “Hopper” GPU offers tremendous raw performance (≈1000 TFLOPS of tensor compute for FP8) and features like FP8/FP4 precision and Transformer Engines that specifically speed up training of massive AI models.
These have proven useful in biotech for training large protein language models and genomic foundation models. Consequently, NVIDIA currently captures the majority of GPU acceleration workloads in biotech, from imaging to molecular AI. Industry adoption reflects this: virtually all of the top 10 pharma companies have active NVIDIA GPU-accelerated projects or collaborations.
AMD’s Niche in HPC Centers
AMD’s Instinct MI200 series GPUs power some of the world’s top supercomputers (e.g. Frontier and LUMI). In life sciences, these large HPC installations have contributed to research breakthroughs – for instance, the LUMI supercomputer (Finland, #8 globally) is used for cancer screening AI (deep learning on pathology slides) and simulating cell membranes at atomic detail (amd.com). AMD GPUs can match or exceed prior-gen NVIDIA performance in many HPC simulations; MI250X essentially packs two GPU dies, and was shown to “match two A100s in performance” on some benchmarks.
However, AMD’s challenge has been software ecosystem. Researchers often find limited documentation and tooling compared to CUDA, making initial setup on AMD more cumbersome (lumi-supercomputer.eu). Codes need porting via HIP or SYCL. That said, initiatives like the ROCm platform and AMD’s work with OpenMP offloading are improving developer experience. In 2024, AMD’s upcoming MI300 APU (combining CPU and GPU) is highly anticipated for HPC AI workloads relevant to biology (it will power the El Capitan exascale system). Some biotech companies are experimenting with AMD GPUs especially when access to NVIDIA is limited (supply constraints in 2024 made headlines) or for cost reasons, as AMD has priced aggressively.
Still, AMD’s presence in pharmaceutical companies’ own data centers remains small; it’s mostly in national labs or academia where AMD hardware is used for life science research.
Intel’s Emerging Role
Intel is positioning itself as a third option that offers open, interoperable solutions. The company’s strategy leverages its ubiquitous CPU presence and oneAPI software to gain a foothold for its GPUs. One advantage Intel often cites is total cost of ownership: for instance, Intel’s Gaudi3 systems deliver almost 3× more throughput per dollar than NVIDIA’s, which could be compelling for budget-conscious biotech startups (nextplatform.com).
Additionally, Intel’s commitment to openness (support for PyTorch, TensorFlow without proprietary lock-in) resonates with academic labs and some companies looking to avoid single-vendor dependence. We see Intel’s impact in collaborations like Broad Institute’s (where replacing legacy GPUs with Intel-optimized CPUs actually sped up workflows) and in specialized areas like secure federated learning (Intel SGX and AI combined for hospitals).
However, Intel faces an uphill battle to gain mindshare. Many bioinformatics professionals are not yet familiar with writing or optimizing code for Xe GPUs or Habana accelerators. Intel’s hardware launched later and sometimes lagged a bit in absolute performance (e.g. Ponte Vecchio lacks Tensor Cores for FP8 that Hopper has, making it less ideal for some AI tasks). But in scientific computing contexts (like molecular dynamics or fluid dynamics in organ modeling), Intel’s GPU Max has proven quite strong (businesswire.com), and its large memory allows training ultra-large bioscience models without partitioning. As of 2025, Intel’s adoption in biotech is mostly via pilot projects and partnerships (as detailed above) rather than widespread production use.
The next 1–2 years will be critical as Intel rolls out Falcon Shores (next-gen unified GPU) – success in a few high-profile case studies (say, a major pharma using Gaudi3 for its AI platform to save costs, or an Intel GPU-based supercomputer achieving a breakthrough in drug discovery) could significantly boost credibility.
In summary, NVIDIA continues to be the default choice for GPU acceleration in drug discovery and genomics due to its performance and mature ecosystem, especially in cloud and enterprise solutions. AMD’s GPUs excel in large-scale HPC installations that tackle biomedical grand challenges, though with less penetration in day-to-day pharma R&D. Intel is rapidly innovating to close the gap – showing competitive benchmark results and forging collaborations in the biotech domain – but it remains the newcomer.
For researchers and CIOs in pharma, this evolving competition is beneficial: it promises more choice of hardware for AI and HPC workloads, potentially lower costs, and cross-vendor software standards that reduce lock-in. As Intel refines its hardware and software for life sciences, we can expect continued improvements in how fast genomics can be analyzed or how accurately an AI model can predict a clinical candidate’s properties – accelerating the pace of innovation in precision medicine and therapeutics discovery.
Member discussion