Lilly’s TuneLab: accelerator, equaliser—or a gilded cage?

Eli Lilly’s latest act of corporate altruism arrived in September 2025 in the form of TuneLab, an artificial intelligence platform dressed up as an equaliser for the drug-discovery industry. The firm claims to have spent more than $1 billion curating preclinical, safety and pharmacological data across hundreds of thousands of molecules, and now offers selected biotechs access to predictive models trained on that treasure trove, supposedly compressing “decades of learning into instantly accessible intelligence” as Reuters and Lilly’s own press cheerfully reported.
The price of admission is not denominated in cash but in data: every partner must contribute experimental results, which are then abstracted through federated learning and folded back into the collective model. The insights circulate, the raw files stay hidden.
What TuneLab actually is
At launch the catalogue consists of eighteen predictive models: a dozen for small molecules, concerned with permeability, solubility, metabolic stability and toxic liabilities, and six for antibodies, preoccupied with aggregation, manufacturability and viscosity, as described by STAT. These models are trained on Lilly’s archives of ADME, safety pharmacology and PK/PD assays, the sort of data that few start-ups could ever hope to amass.
The platform itself is hosted by a third party and operates on the principle of federated learning: the models travel, the data does not. Each biotech installs or fine-tunes a local copy; only encrypted parameter deltas, the so-called gradients, are aggregated centrally, a design that, according to BioPharma Dive, keeps assay files firmly behind company firewalls.
In day-to-day use, a chemist might submit a structure in SMILES or SDF form, or a protein engineer a FASTA sequence. TuneLab then returns a ranked set of predicted liabilities: hERG inhibition, CYP metabolism, permeability and the like. When the wet-lab assays—whether bioactivity, DMPK or SEC-MALS for antibodies—deliver their verdicts, those results are normalised and pushed back as encrypted updates, sharpening the models for all participants.
The roadmap includes still more ambitious promises: in-vivo predictors for exposure and toxicity, and an ADMET-in-vivo model co-built with insitro, leveraging Lilly’s unusually rich pharmacokinetic datasets, as that firm’s announcement made clear.
Under the hood
The architectures themselves are hardly revolutionary, but the scale and curation matter. For small molecules, Lilly almost certainly relies on graph neural networks and message-passing schemes that treat atoms as nodes and bonds as edges, trained jointly across multiple endpoints. Transformer encoders applied to SMILES sequences offer another path, providing scaffold-level generalisation, though always with the risk that tokenisation quirks will distort chemistry. Three-dimensional models, whether distance–angle graphs or equivariant networks, are used where conformational properties dictate permeability or metabolic hotspots. Generative components, perhaps reinforcement-learning agents or diffusion models, can then suggest new molecules that optimise predicted profiles subject to synthetic feasibility.
On the biotherapeutic side, protein language models encode heavy- and light-chain sequences. From these embeddings, one can infer charge patches, hydrophobicity, isoelectric points and liabilities within the complementarity-determining regions (CDRs). Surrogate models then predict colloidal stability, viscosity at formulation concentrations and expression titres, trained on biophysical assays such as SEC, dynamic light scattering and differential scanning fluorimetry.
All of this becomes more powerful through multi-task learning. Many endpoints share the same hidden determinants: lipophilicity influences both solubility and permeability; CDR hydrophobicity affects both aggregation and clearance. Instead of training a different model for each task, a shared encoder is used, with separate output “heads” for each endpoint:
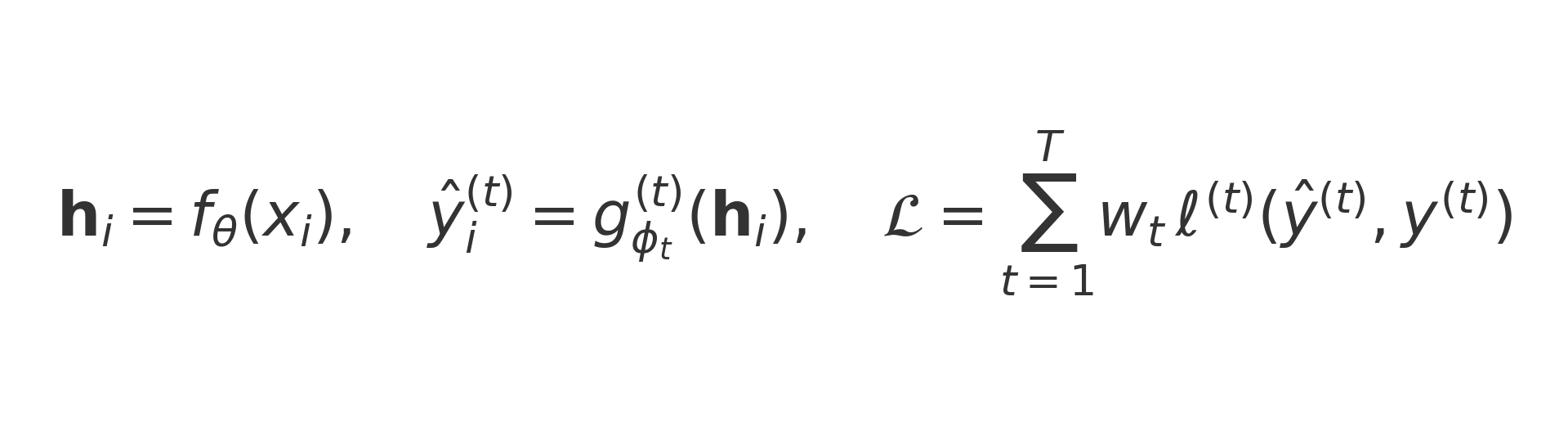
In plainer English: the input x-i (a molecule or antibody sequence) is converted into a shared internal representation h-i. Each task t (toxicity, solubility, viscosity, etc.) then gets its own prediction, written here as y-hat superscript t. The overall loss, denoted L, is simply the weighted sum of the errors across all tasks. The weights w-t decide how much each task contributes.
Predictions are only useful if the model knows when not to trust itself. Hence the use of ensembles or Monte Carlo dropout for uncertainty, and an out-of-distribution check based on the Mahalanobis distance D_M(h), which measures how far a latent point h lies from the centre of the training distribution defined by mu and Sigma. If D_M(h) is unusually large, the model flags the input as unfamiliar and urges caution. Example: if typical compounds give D_M ≈ 2 but a new one yields D_M = 8, treat that prediction as low-confidence.
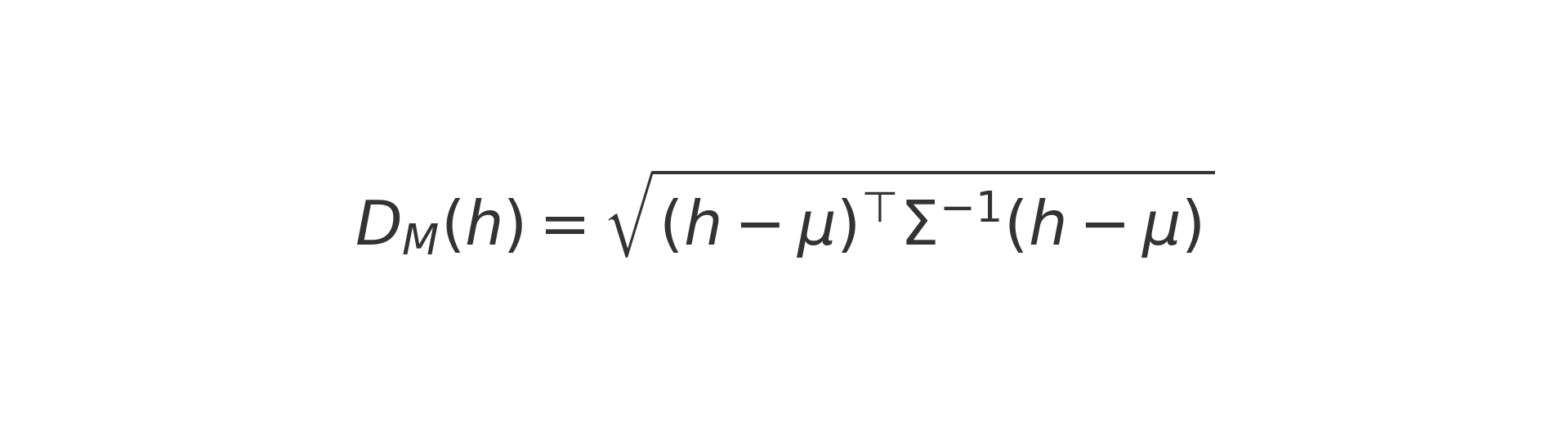
Finally, TuneLab’s collaborative setup requires federated averaging. Each biotech trains locally and produces theta_k. The server then forms a data-weighted average to obtain theta^(t+1), where partners with more data (n_k) have greater influence. Secure aggregation ensures the server only sees the sums, not any individual update; optional noise can be added so that even indirect reconstruction of private data is infeasible.
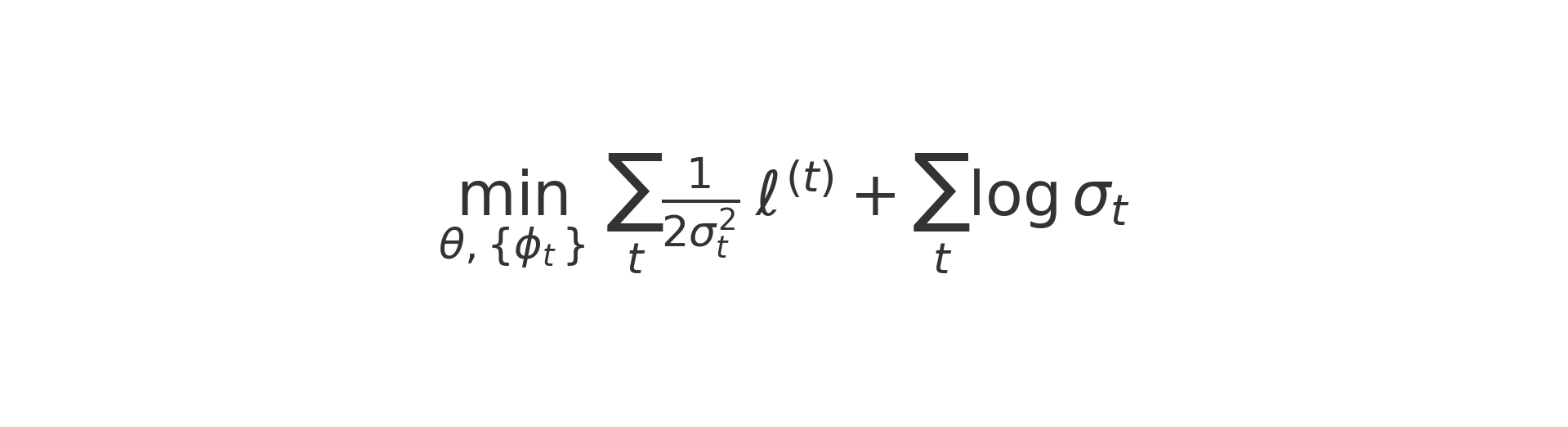
Data plumbing
Less glamorous but equally critical is the curation of the data pipeline. Small molecules are normalised into canonical SMILES and InChIKeys, stripped of salts and tautomers, and adjusted for physiological charge states. Descriptors include circular fingerprints and RDKit-derived features; three-dimensional conformers are generated with ETKDG and minimised with MMFF94. Bioassay outputs are mapped into unified units, annotated by ontology, and corrected for censoring and batch effects. DMPK metadata—species, microsomal versus hepatocyte matrices, protein binding, transporter contexts—are standardised. Antibody datasets capture sequence numbering, calculated pI, biophysical readouts of stability and viscosity, and expression titres. To make this all tractable, TuneLab imposes governance: immutable lineages showing which experiments fed which model version, model cards describing scope and limitations, and reproducibility standards for predictions that inform go/no-go decisions. Without this ruthless curation, a billion-dollar dataset risks degenerating into a billion-dollar confounder.
Economics of exchange
For the biotechs, the appeal is cost and time compression. Chemistry can be prioritised, dead series pruned earlier, animal studies reduced, and lead optimisation accelerated. The capability uplift is significant: industrial-grade models without the overhead of an in-house machine-learning group. Access to the wider Catalyze360 ecosystem—Lilly Ventures capital, Gateway Labs benches and the credibility that comes with Lilly’s imprimatur—sweetens the pot, as noted by Fierce.
For Lilly, the flywheel spins even faster. Every partner’s assay becomes a free improvement to its models. Proximity to promising science offers a first look at future licensing or acquisition targets, as BioPharma Dive noted. Reputation is burnished: Lilly appears benevolent, forward-looking, aligned with regulators’ push for in-silico testing as Reuters observed. Internally, improved externalised models also lift Lilly’s own pipelines—a dividend rarely highlighted. STAT put it pithily: access is free; the catch is Lilly gets your data.
Where the bars lie
The bars of the cage are subtle but real. Federated updates still encode partner know-how; Lilly owns the improved model even if a start-up departs, leading to asymmetry over time. The contribution imbalance is stark: Lilly’s is historic, partners’ are ongoing. If access terms change later, switching costs are formidable. Intellectual property may formally stay with the biotechs, but soft power nudges future deals towards Lilly. Privacy, though robustly protected, is not infallible; with enough rounds, clever attacks could infer fragments. Contribution can also end up helping rivals: a shared model that improves permeability predictions aids everyone, oncology competitor included. And the performance of AI in drug discovery has been modest, sometimes disappointing, as BioPharma Dive drily observed. Models encode biases; they are tools, not oracles.
Circle and insitro
The choice of Circle Pharma and insitro as initial partners is telling. Circle focuses on macrocycles, notorious for permeability and oral bioavailability challenges. By contributing its ring-strained, polar surface area-confounding molecules, Circle expands the envelope of TuneLab’s models. It gains more accurate triage; Lilly gains exposure to a sparse and valuable subspace, as Circle’s own release underlined. Insitro, meanwhile, builds the in-vivo bridge. Most property models fail when confronted with living systems. Lilly’s PK/PD data, rare in scale, enable a robust ADMET-in-vivo surrogate that could catch failures earlier and save fortunes downstream, as its announcement argued.
How to play the game without losing
Prudent start-ups will impose guardrails. Contribute labels and embeddings rather than raw traces where possible. Demand calibrated probabilities and conformal prediction to avoid confidently wrong calls. Enforce out-of-distribution alarms so the model cannot steer portfolios where it has no business. Audit governance through model cards, versioned snapshots and contribution meters that show whose data moved which head. Insist on explicit clauses: no implied rights of first refusal, freedom to run other collaborations, kill-switches to pause contributions when programmes become strategic, export parity for frozen models at termination, and clarity on security posture.
Fairness of contribution: the Shapley value
A persistent worry in federated systems like TuneLab is fairness: how do you know whether the data your company contributes is really worth as much as the benefit you receive? One way economists and game theorists have attacked this problem is with the Shapley value. Originally designed for cooperative games, the Shapley value attributes the total gain of a coalition to its members based on their marginal contributions.
In words: you imagine all possible orders in which companies could join the collaboration, and for each order you measure how much extra performance a given company’s data adds when it enters. The Shapley value is the average of those marginal contributions across every possible order. It is mathematically fair in the sense that everyone’s value sums to the total improvement, and no one is penalised or over-rewarded for coming early or late.
Let phi_i be the Shapley value for company i. Let N be the set of all companies, and S any subset of N that does not include i. Define V(S) as the model’s performance (for example, AUROC or RMSE) when trained on the data of subset S. Then:
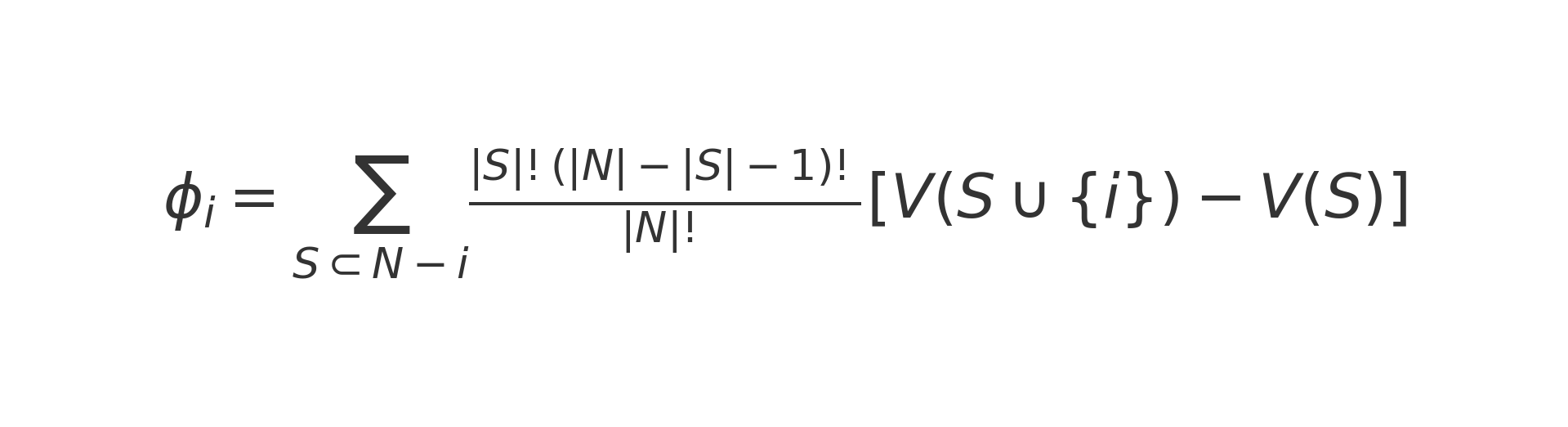
This weighting with factorial terms ensures fairness: it accounts for all possible positions company i could take in the joining order.
In plain words:
V(S)= model accuracy with only companies in subsetSV(S ∪ {i}) - V(S)= marginal benefit of adding company iphi_i= average marginal benefit across all possible orders
Example calculation. Suppose we have three companies {A, B, C}.
- Training with A alone gives AUROC = 0.70.
- Adding B lifts it to 0.75.
- Adding C instead lifts it to 0.73.
- Training with all three yields 0.80.
By computing the marginal lift each time a company joins (averaged across permutations), one can calculate that B’s phi_B is higher than C’s, because B consistently adds more to model performance.
In practice, computing the full Shapley value exactly is infeasible once N is large (it requires evaluating all subsets). Instead, approximations are used: influence functions, or leave-one-out deltas (V(N) - V(N \ {i})), which give a tractable estimate of each partner’s contribution. The principle, however, is clear: contributions can be measured, and fairness can at least be approximated.
How to know if it works
Key indicators include the proportion of ideas killed in silico, the time from hit to lead series, the assay-per-kill ratio, and the fraction of retested predictions that hold water. Model metrics such as AUROC, RMSE, calibration error and conformal coverage should be tracked. Lagging outcomes—animal repeats avoided, IND cycle times, first-in-human discontinuations—are the ultimate proof. Portfolio health, measured by the share of projects in high-uncertainty, high-novelty quadrants, signals whether the model is guiding innovation or suffocating it.
Industry context
Consortia such as MELLODDY have already shown that federated learning can coax rivals to share models without sharing data. TuneLab transposes that logic to the pharma-biotech axis, wrapping it inside Catalyze360 alongside capital and infrastructure. For Lilly it is philanthropy with internal rate of return: the more others use it, the better Lilly’s models become; the better the models, the more others will use it. BioPharmaTrend called it flywheel economics, and they are right.
The verdict
Admire the gilding; test the bars. TuneLab is an impressive attempt to turn hard-won laboratory knowledge into portable intelligence. If it saves months of discovery time and nudges more viable compounds into the clinic, it is value enough. But the economics compound inexorably to the platform owner. Biotechs would be wise to enter with eyes open, insist on off-ramps and measure contributions. If Lilly manages to keep the exchange fair and transparent, the cage may feel less like confinement and more like a sophisticated co-working space for molecules—still Lilly’s building, but worth the rent in data.
Member discussion