Nvidia, AMD, and the Battle for Biotech AI Hardware in 2025

The biotech industry’s appetite for artificial intelligence has grown insatiable. From AI-driven drug discovery and protein folding to generative chemistry and medical imaging, cutting-edge models are churning through terabytes of data in pursuit of new medicines and insights. These tasks – folding a protein with AlphaFold, screening billions of molecules, or parsing multimodal biomedical data – demand staggering computational power. In 2025, that power largely comes from specialized AI hardware: advanced GPUs and accelerators running sophisticated software stacks.
Nvidia has long dominated this domain, its GPUs and CUDA software nearly synonymous with deep learning. AMD, eager to catch up, has introduced powerful Instinct accelerators and the ROCm open software platform as an alternative. Other contenders – from Intel’s AI chips to Google’s TPUs and various startups – also vie for a slice of the healthcare AI hardware market.
Investors and biotech CTOs now face pressing questions: Can AMD or any competitor meaningfully dent Nvidia’s lead in biotech AI infrastructure? How do their hardware and software ecosystems compare in real-world scientific workloads? Are promises of speed and efficiency translating into better drug discovery pipelines and lower R&D costs, or are developers hitting walls of frustration? This report takes a hard, analytical look at the state of AI hardware in biotech circa 2025 – examining GPUs and accelerators, their software ecosystems (CUDA vs ROCm, Nvidia Clara, OpenFold, etc.), and the critical factors of usability, model compatibility, support, cost, energy efficiency, and adoption on the ground.
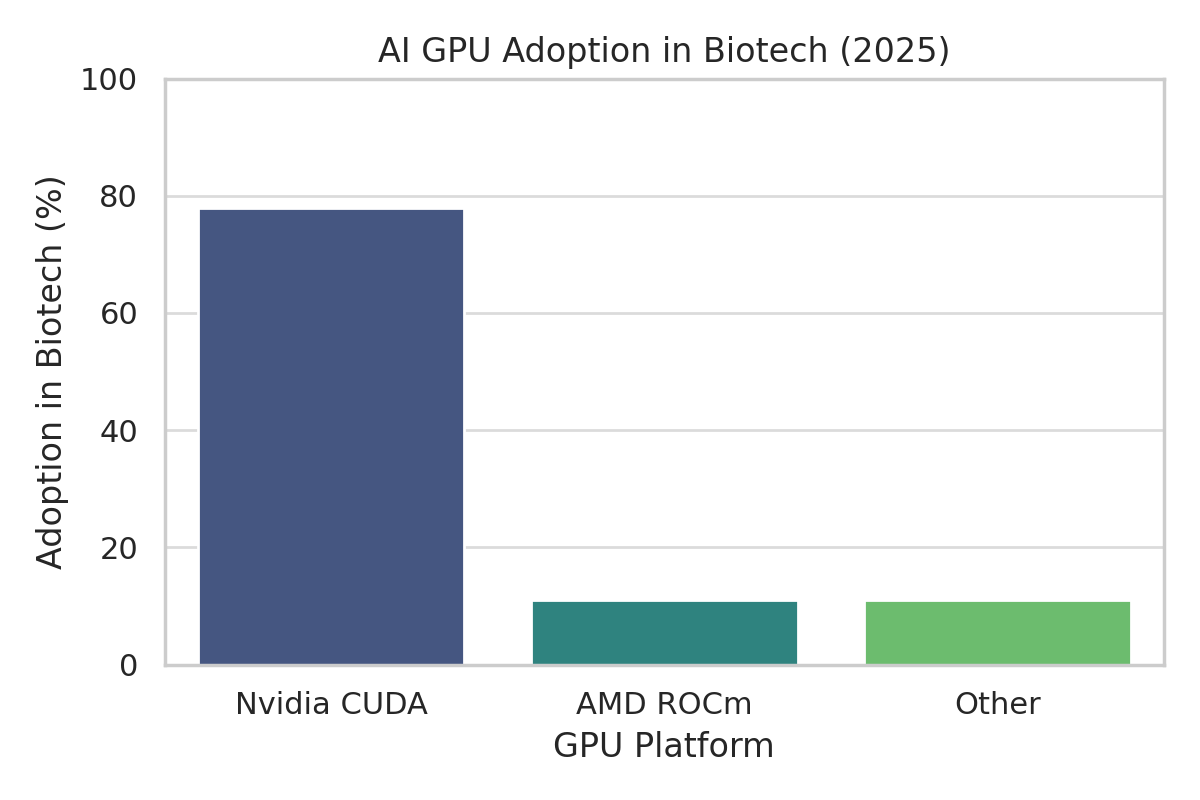
We will cut through marketing hype to assess whether AMD’s moves are closing the gap or if Nvidia’s empire still reigns unchallenged in the labs. Along the way, we’ll hear what engineers are saying at the bench: the triumphs and travails of using these platforms for life sciences.
The AI Hardware Landscape for Biotech in 2025
Parallel Revolutions in Biology and Computing: A perfect storm of progress in both biotechnology and AI has put GPUs at the center of modern life science research. Just a few years ago, a biologist might use GPUs sparingly – perhaps to render molecular images or accelerate a genomic alignment. Now, entire biotech companies are built around training transformer models for protein design or running generative adversarial networks to propose new drug molecules, tasks that are impractical without massive GPU acceleration.
Breakthroughs like DeepMind’s AlphaFold2 (and its open-source cousins like OpenFold) proved that neural networks could solve grand challenges like protein 3D structure prediction, but only after training on specialized hardware for weeks (rchsolutions.com). Similarly, startups in generative chemistry employ large language models (LLMs) and graph neural networks to invent novel compounds, requiring clusters of GPUs to crunch quantum-chemical data and learn complex molecular representations. Medical imaging AI – radiology, pathology – uses deep convolutional networks that also thrive on GPU parallelism. In short, wherever there is structured biological data – sequences, structures, images, medical records – there is likely a GPU-driven AI model trying to find patterns in it.
Nvidia’s Near-Monopoly: Nvidia recognized this trend early and cultivated a near-ubiquitous presence. Its hardware and software platform has become the default choice for AI in biotech as in most domains. As of 2025, Nvidia A100 and H100 GPUs (data-center cards from the Ampere and Hopper architectures, respectively) are staples in pharma R&D centers, cloud AI services, and supercomputers used for life science. Nvidia’s upcoming Blackwell generation (often referenced as GB100/GB200 series) is highly anticipated as the next leap in performance (genengnews.com).
A telling indicator of dominance: when DeepMind released AlphaFold, the reference implementation was built around Nvidia GPUs and Google TPUs – no mention of AMD. Many open-source bio-AI projects assume CUDA-compatible devices by default. Nvidia has leveraged this incumbency to build an entire stack for healthcare: the Nvidia Clara platform spans imaging, genomics (e.g. GPU-accelerated DNA sequencing pipelines), and drug discovery with domain-optimized libraries (nvidia.com).
On top of that, Nvidia offers BioNeMo™ (a generative AI toolkit for biopharma) and has fostered industry partnerships – from providing hardware for Recursion’s BioHive-2 supercomputer to funding startups like Genesis Therapeutics (genengnews.com). As CEO Jensen Huang quipped, biology is now a data science: “we’ve digitized… proteins and genes… If we can learn the patterns from it, we can understand its meaning… and maybe generate it as well. The generative revolution is here”. In practical terms, Nvidia is positioning itself not just as a hardware vendor but as a full-stack solutions provider for biotech AI.
AMD and the Other Contenders
Meanwhile, AMD – historically the underdog in GPUs – has been racing to offer an alternative. In HPC (high-performance computing) circles, AMD scored big wins by powering the Frontier supercomputer (the world’s first exascale system) entirely with AMD CPUs and GPUs, proving its silicon can rival Nvidia’s in raw calculations. AMD’s Instinct™ GPU line, especially the MI200 series (deployed in Frontier and Europe’s LUMI supercomputer), showed strong theoretical performance – often beating Nvidia A100 in FP64 compute and memory bandwidth on paper.
But making a dent in AI required more than hardware specs; it meant cultivating a software ecosystem to compete with CUDA. AMD’s weapon here is ROCm (Radeon Open Compute), an open-source platform analogous to CUDA. We will delve into ROCm vs CUDA shortly, but suffice it to say that AMD’s challenge has been less about manufacturing capable chips – it has some, including the newer MI300/MI350 series – and more about convincing the world that using them won’t be a painful adventure.
Other competitors also lurk: Intel’s Habana Gaudi accelerators have been offered on some cloud platforms for AI training at lower cost, and Google’s TPUs (tensor processing units) continue to power Google’s own biotech AI efforts (e.g. DeepMind likely trained AlphaFold on Google TPUs originally). A few startups like Graphcore (IPUs), Cerebras (wafer-scale engines), and SambaNova have pitched their chips for scientific AI workloads, and even specialized ASICs (application-specific chips) for genomics or molecular dynamics exist. But as of 2025, none of these have achieved broad adoption in biotech – they remain niche experiments, often hampered by limited software support or availability.
It is Nvidia vs AMD that defines the main front of competition for biotech AI infrastructure, with others playing supporting roles in certain regions or projects.
Demand Outstrips Supply
One striking feature of 2023–2025 was that demand for AI compute exploded (driven by the global craze for large language models and generative AI), leading to shortages of top-tier GPUs. Nvidia’s H100 became a coveted resource; wait times and prices soared. This macro trend has implications for biotech: a drug discovery startup cannot iterate quickly if it can’t get enough GPU time.
In this environment, AMD saw an opening – offering potentially more available or cost-effective hardware. Cloud providers like Oracle even pounced on AMD’s newest GPUs to build massive clusters advertised at better price/performance. In June 2025, Oracle announced it will offer up to 131,072 of AMD’s MI355X GPUs in OCI (Oracle Cloud Infrastructure), claiming “more than 2× better price-performance” for large-scale AI workloads compared to the previous generation.
Oracle’s simultaneous deployment of a comparable Nvidia Blackwell-based supercluster underscores that big players feel the need to double-source – to have both Nvidia and AMD options on tap. For investors, such moves signal that AMD is at least competitive enough to warrant inclusion in hyperscale build-outs, even if Nvidia remains the primary choice. Regions like China, facing U.S. export restrictions on Nvidia’s fastest GPUs, have also spurred interest in alternatives (either AMD, if allowed, or domestic chips like Huawei’s Ascend).
We’ll discuss later how China’s quest for AI hardware self-sufficiency has led to brute-force approaches (e.g. using 4× more power to match Nvidia systems), a testament to the difficulty of catching up to Nvidia’s efficiency.
In summary, the stage is set: Nvidia as the entrenched leader with a vast ecosystem and deep involvement in biotech; AMD as the ambitious challenger with powerful new hardware and a rallying cry of openness; and a cast of minor players filling specific gaps or regional needs. Now, let’s examine each in detail, and more importantly, how they stack up where it counts – in real-world biotech AI use cases.
Nvidia: The Incumbent with a Full-Stack Ecosystem
It is often said in IT that “nobody gets fired for choosing IBM.” In the world of AI infrastructure, one might say nobody gets fired for choosing Nvidia. The company has carefully cultivated an image (and reality) of providing not just chips, but solutions. For biotech organizations venturing into AI, Nvidia offers a reassuring one-stop shop: state-of-the-art GPUs, a mature and well-documented software stack, and even domain-specific toolkits and reference workflows for life sciences.
It helps that Nvidia’s hardware has consistently led most performance metrics that AI researchers care about – from raw compute throughput to developer productivity – creating a positive feedback loop of adoption.
Hardware Performance and Features
Nvidia’s current flagship for AI training in 2025 is the H100 GPU (built on the Hopper architecture, 4nm process). An H100 packs around 80 billion transistors and delivers on the order of 1,000 TFLOPS (1 quadrillion ops per second) of FP16/BF16 tensor compute thanks to its specialized Tensor Cores (for context, that’s roughly 6× the FP16 performance of an older A100).
It comes with 80 GB of ultra-fast HBM2e memory in its PCIe variant (and up to 94 GB in some SXM models), providing ~2 TB/s of memory bandwidth. This combination of high compute and high memory bandwidth is critical for training large models like generative transformers – and also for memory-hungry tasks like training AlphaFold models which ingest multiple sequence alignments and large structure data. Nvidia has also introduced mixed-precision and accelerated formats (like TensorFloat32 and FP8) that allow faster training without sacrificing much accuracy, supported natively in its silicon and software.
For multi-GPU setups, Nvidia’s NVLink high-speed interconnect and NVSwitch networking enable scaling to dozens or hundreds of GPUs with fast communication (important for parallel training of one model across GPUs). This is embodied in Nvidia’s DGX systems and HGX server platforms – essentially “AI supercomputer in a box” offerings that many pharma companies and research labs deploy. In biotech, where a single model (say a protein-folding network or a drug-generative model) may need to be spread across 8 GPUs to fit into memory, these interconnects and the supporting libraries (NCCL for communication) are a big deal.
By 2025, Nvidia’s new NVLink Switch System (Fusion) and concepts like Grace Hopper (GH200) – which combine an H100 with an Nvidia Grace CPU and shared memory – further extend this scaling. It’s not just raw speed, but the ability to efficiently use multiple GPUs together, that gives Nvidia an edge in large-scale biotech AI projects (for instance, a massive protein simulation or an ultra-deep learning pipeline for genomic data).
CUDA and the Software Moat
If Nvidia’s hardware is the body, CUDA is the soul. The CUDA toolkit (Compute Unified Device Architecture) has become the de facto standard API for GPU computing. Crucially, all major deep learning frameworks (TensorFlow, PyTorch, JAX, MXNet, you name it) come with built-in CUDA support and optimized kernels for Nvidia GPUs. Nvidia supplements this with a plethora of performance libraries – cuDNN for deep neural network primitives, cuBLAS for linear algebra, TensorRT for optimized inference, and domain-specific libraries like Parabricks for genomic analysis or cuQuantum for quantum chemistry simulations.
For a biotech software developer, this means that using Nvidia hardware often “just works.” Need to train a model? PyTorch + CUDA will automatically use GPU with highly optimized routines (nvidia.com). Need to accelerate a genome alignment? Nvidia’s Clara Parabricks toolkit can run DNA sequence mapping 30× faster than CPU solutions, fully leveraging A100 GPUs (a pitch Nvidia has made to genomics labs).
This extensive ecosystem has been described as Nvidia’s software moat, and rightly so. Over a decade-plus of CUDA’s existence, Nvidia nurtured a community of developers and researchers who have written countless CUDA-accelerated applications. Biotech is no exception: many academic teams have CUDA code for say, molecular dynamics (the popular AMBER and GROMACS MD simulators have CUDA acceleration), cryo-EM image reconstruction, and more.
Nvidia’s Clara Discovery suite provides pre-trained models and pipelines for drug discovery, including molecular generative models (e.g. MegaMolBART for molecule generation) and protein docking/screening workflows (nvidia.com). And when Nvidia sees a gap, it fills it: e.g., recognizing the rise of generative AI in biology, Nvidia rolled out BioNeMo – a service and framework with generative chemistry and biology models (protein sequence generators, reaction predictors, etc.) which developers can fine-tune with their own data. In effect, Nvidia has blurred the line between being a hardware provider and a life-science AI platform provider.
This full-stack approach has tangible benefits. Case study: Recursion Pharmaceuticals, a prominent AI-driven drug discovery company, partnered with Nvidia to build BioHive-1 and BioHive-2, some of the most powerful private supercomputers in pharma. These clusters use hundreds of Nvidia GPUs to ingest Recursion’s proprietary cellular imaging data and train computer vision models to identify potential therapeutics. Nvidia didn’t just sell them chips; it collaborated on optimizing the workflows, likely leveraging Clara for imaging and providing engineering support.
Similarly, Nvidia’s venture arm has invested in startups like Genesis Therapeutics which apply graph neural nets to drug design, ensuring that those startups have early access to Nvidia’s latest tech and are deeply tied into the CUDA ecosystem. In an ironic twist, AMD’s first marquee biotech customer, Absci, still acknowledged that the partnership “does not preclude… partnerships with other AI chip companies” (genengnews.com) – an oblique way of saying Absci might use Nvidia too – whereas many Nvidia-aligned biotechs don’t even consider AMD yet, as Nvidia covers their needs.
Biotech Use Cases and Nvidia’s Fit
Let’s briefly map common biotech AI tasks to Nvidia’s offerings:
Protein structure prediction (AlphaFold/OpenFold)
These models involve hefty matrix multiplications (attention mechanisms, etc.) and custom ops for triangle updates, etc. AlphaFold was initially implemented in TensorFlow (with JAX for AlphaFold 2/3). Nvidia GPUs handled this well; indeed, UT Austin researchers found AlphaFold’s inference performance “quite similar on AMD and NVIDIA GPU servers” in their tests (cloud.wikis.utexas.edu), suggesting the workload is well-supported by both, but Nvidia had the advantage of being the default environment. For training new models like AlphaFold3, which uses JAX, Nvidia’s dominance is felt: a UCL team noted the official AlphaFold3 code was built for Nvidia Docker containers, and porting it to AMD ROCm required manually swapping out packages and dealing with version mismatches.
Nvidia’s JAX support (via CUDA) is first-class, whereas AMD’s JAX support lags (the team found AMD’s official JAX container was 3 versions behind the needed version). In practice, if you want to stand up AlphaFold or retrain it, Nvidia GPUs and Google TPUs are the straightforward options, while AMD is an adventure (more on that in the AMD section).
Molecular dynamics (MD) simulations
These are somewhat different from AI, relying on classical physics simulations but often accelerated on GPUs (e.g., using CUDA in the AMBER MD package). Nvidia’s FP64 performance and excellent developer tools for simulation have made it a staple in MD. The new H100 has lower FP64 than its FP16 (since it’s optimized for AI), but Nvidia offers separate A800/A100X and other variants with strong FP64 for HPC. Moreover, biotech simulations sometimes use mixed precision – which Nvidia’s hardware and libraries (like cuBLAS with tensor cores) handle with care to maintain accuracy.
AMD’s GPUs actually often boast higher FP64 theoretical FLOPs (MI250X was advertised to beat A100 in FP64), which gave them some HPC wins. But if the simulation software isn’t ported to ROCm, that advantage is moot. Nvidia also integrates simulation and AI workflows, e.g. using GPUs to both simulate and run AI-driven analyses on the fly, under one ecosystem (they demonstrated ML-driven simulation steering with CUDA).
Generative Chemistry (e.g. variational autoencoders for molecules, diffusion models for drug design)
These models are typically built in PyTorch or TensorFlow. Nearly all major chemistry deep learning frameworks (DeepChem, Open Catalyst, etc.) expect CUDA GPUs by default. Nvidia GPUs excel at the tensor operations in these models, and with libraries like cuDNN and TensorRT, Nvidia even helps deploy trained models for inference (e.g. accelerating a generative model to propose molecules in real-time). For example, Nvidia showcased MegaMolBART (a transformer for molecule generation) as part of Clara Discovery and likely optimized it on their GPUs.
Large Language Models on biomedical text (BioGPT, BioBERT, etc.)
The training of any LLM, whether general or domain-specific, is usually done on Nvidia hardware due to scale. As one anecdote, a large pharma might fine-tune a GPT-style model on internal text: using Nvidia’s distributed training libraries (Megatron-LM, which Nvidia open-sourced, or NeMo toolkit) makes this relatively turnkey on a multi-GPU cluster. Nvidia even put out reference implementations for GPT-3 scale training on DGX SuperPODs (their clusters).
For inference serving, Nvidia’s TensorRT can optimize LLMs for fast response (though with 2025’s giant models, even Nvidia has to get creative – see their transformer engine and Sparsity support). Simply put, the entire LLM craze has run on Nvidia GPUs, so any bio-specific offshoots (like specialized LLMs for protein sequences or medical literature) naturally run there too, unless an organization has a compelling reason to migrate.
Medical Imaging AI
This involves applying CNNs or vision transformers to images like MRI scans, pathology slides, etc. Nvidia’s advantage here is twofold: first, CNN training is an “old hat” for CUDA libraries (cuDNN has years of optimizations for convolution ops), so it’s very fast and efficient. Second, Nvidia’s Clara Imaging offers ready-to-use models and even an end-to-end pipeline (from reading DICOM images to outputting results) accelerated on GPUs (nvidia.com). Many hospitals and researchers use Clara or NVIDIA’s SDKs to train or depl
oy models that flag tumors in images or do segmentation. Also, Nvidia’s TensorRT and even GPUs in edge form factors (Jetson, etc.) allow deployment in medical devices – beyond the datacenter realm but relevant to healthcare AI. AMD has no comparable presence in this segment yet.
To sum up Nvidia’s position: It’s not just about having the fastest chip (though Nvidia often does or is close). It’s the breadth of the ecosystem and support. Developers in biotech know that if they hit a snag on Nvidia, there’s likely documentation or forum answers, or an Nvidia engineer willing to help. The trust is such that even when AMD’s hardware offers more VRAM or FLOPs for the dollar, many stick with Nvidia to avoid potential porting headaches.
A Wall Street analyst’s 2025 downgrade of AMD bluntly concluded Nvidia would “continue to trail… well into 2025” and noted that Nvidia was stepping up production of its next-gen Blackwell GPUs to further distance itself (genengnews.com). Indeed, Nvidia’s market cap and stock surged through 2024 into 2025, reflecting investor confidence that its AI dominance (including in life sciences) will translate to revenue. In the life-science AI gold rush, Nvidia sells the shovels – and very good shovels at that.
However, no discussion is complete without examining the challenger. AMD argues that Nvidia’s dominance is not unassailable – that with the right hardware improvements and by eroding the CUDA software moat, they can offer a compelling alternative. Let’s critically evaluate AMD’s progress on those fronts and see how its promises stack up against reality.
AMD’s Bid to Break Nvidia’s Dominance
In the narrative of David vs Goliath, AMD certainly paints itself as a kind of David in the GPU world – albeit a David with a multi-billion-dollar war chest and some formidable technology of its own. AMD’s pitch to the AI community (and by extension to biotech) has been: We have GPUs just as powerful as Nvidia’s, we offer more open software, and we’ll give you more bang for your buck. 2025 is a crucial year for AMD to prove this pitch, as it launches new hardware and desperately tries to mature its software stack to a point where using AMD GPUs isn’t an exercise in masochism.
Instinct MI200, MI300, MI350 Series – the Hardware
AMD’s data-center GPU lineup, branded Instinct, has iterated rapidly. The Instinct MI250X (CDNA2 architecture, 6nm, launched ~2021) was a dual-die GPU with 128 GB of HBM2e memory and impressive specs – about 95 TFLOPS FP16 (without sparsity) and 47.5 TFLOPS FP64, per official numbers, which actually exceeded Nvidia A100’s 19.5 TFLOPS FP64 and ~78 TFLOPS FP16 in raw throughput (tomshardware.com). Memory bandwidth on MI250X was also higher (3.2 TB/s vs 2.0 TB/s on A100).
This is why Frontier supercomputer chose AMD: for HPC workloads like physics simulations, MI250’s muscle (especially in double precision) was a winner, and tight integration with AMD CPUs helped too. For AI, MI250 was competitive on paper; indeed one Reddit analysis noted MI250 ends up 2–3× the performance of A100 on a PyTorch BERT benchmark in certain configurations. But hardware on paper and real-world AI training are different stories – many early buyers of MI250 found that achieving those gains required significant software optimization that wasn’t yet available out-of-the-box for AMD.
Fast-forward to Instinct MI300X (CDNA3, 5nm, launched 2023) and new MI350X/MI355X (CDNA4, 3nm, launched mid-2025). These GPUs show AMD’s evolving strategy. The MI300X came with a whopping 192 GB of HBM3 memory, an enormously attractive feature for AI models that push memory limits (for example, it can fit larger batch sizes or bigger sequence lengths without sharding across GPUs). A technical deep-dive by Chips and Cheese revealed MI300X has a massive 256MB on-die “Infinity Cache” (L3) and robust caching that delivered 3× the cache bandwidth of an Nvidia H100 in tests.
In fact, MI300X “often vastly outperforms Nvidia’s H100” in low-level memory and compute benchmarks, indicating a very strong architecture. However, some caveats applied: initial comparisons pitted MI300X against a PCIe H100 (a weaker variant), and inference performance differences in real models depended on software tuning.
Still, MI300X demonstrated that AMD could innovate technically – it was arguably more balanced for HPC+AI mixed workloads, with huge memory and cache and high FP64 alongside competitive AI throughput. One example: FluidX3D, a fluid dynamics AI-assisted simulation, showed MI300X achieving ~1.86× the performance of H100 (PCIe)m. On AI inference, test results were mixed; MI300X could shine on very large batch inference due to memory, but H100 led on smaller batches or with better-optimized software paths (runpod.io).
The MI350X/MI355X (CDNA4) launched in 2025 take AMD’s approach further. Interestingly, AMD bifurcated its line: the MI355X is specifically optimized for AI inference, even at the expense of some general-purpose throughput. According to AMD, the MI355X actually has lower FP32/FP64 peak performance than MI300X but much higher low-precision (INT8/FP8) throughput and adds new FP4/FP6 support.
In other words, AMD is acknowledging that to compete in AI, you sometimes trade off HPC-centric specs for AI-specific ones. The MI355X carries 288 GB of HBM3e memory (an insane amount – 1.5× more than MI300X, and 3.6× more than an 80GB H100) and achieves around 10,066 TFLOPS in FP8/INT8 (via its Matrix Cores). Its FP64 is ~79 TFLOPS (higher than H100’s ~67 TFLOPS), reinforcing that AMD still caters to HPC too.
The cost? Power. Each MI355X can consume up to 1,400 W (!), and is delivered in a liquid-cooled OAM form-factor module. Essentially, AMD built a behemoth meant to slug it out with Nvidia’s top chips on large inference workloads, perhaps expecting that datacenters will accept higher power draw if the performance per GPU is very high. AMD claimed MI355X offers 1.6× the memory, equal bandwidth, and 2× the FP64 performance of Nvidia’s top Blackwell GPU (B200).
These figures suggest (datacenterdynamics.com) AMD positioning MI355X not just as an alternative, but in some respects superior, for large models and HPC. Indeed, Oracle’s decision to plan a zettascale cluster with 131k MI355Xs was predicated on promised 2× price-performance vs AMD’s prior gen (and presumably competitive vs Nvidia).
It’s worth noting that AMD often competes by offering more memory or FLOPs per dollar, which can be very relevant in biotech: e.g., training a next-gen AlphaFold with longer protein sequences might be feasible on a single MI300X (with 192GB) whereas it would spill out of an 80GB card – meaning you’d need multiple Nvidia GPUs, negating cost advantages. Similarly, more memory can benefit generative models that need to hold large chemical libraries or knowledge graphs in memory.
ROCm: Bridging the Software Gap or Pain Point?
Here lies AMD’s Achilles’ heel historically. The ROCm (Radeon Open Compute) software stack is AMD’s answer to CUDA. It includes the HIP programming language (a sort of CUDA-runtime clone that can compile code for AMD GPUs), libraries equivalent to Nvidia’s (MIOpen as an analog to cuDNN, RCCL analogous to NCCL for multi-GPU communication, etc.), and runtime drivers. AMD touts ROCm as open-source and collaborative. In principle, a lot of modern AI frameworks have some level of ROCm support – for instance, PyTorch has had ROCm builds for a while, and TensorFlow has a ROCm variant (cloud.wikis.utexas.edu).
In practice, however, developers frequently ran into problems using them. The prevailing sentiment from many developers has been that “ROCm is painful to use.” This quote from a 2025 analysis by ChipStrat (chipstrat.com) encapsulates it: “The software is terrible! … I’ve tried 3 times in the last couple years to build [PyTorch for ROCm], and every time it didn’t build out of the box… or returned the wrong answer. In comparison, I have probably built CUDA PyTorch 10 times and never had a single issue.”These were the words of famed hacker George Hotz, reflecting frustrations shared widely on forums.
So what exactly are the issues? Users cite: poor driver stability (kernel panics), incomplete support for many GPU models, confusing documentation, and a general lack of polish. One HackerNews thread from 2024 was literally titled “Ask HN: Why hasn’t AMD made a viable CUDA alternative?” and top answers pointed out that AMD did not prioritize ROCm across all its products, leading to fragmentation and bugs.
“There is no ROCm support for their latest [consumer] AI chips… The drivers are buggy. It’s just all a pain to use. And for that reason the community doesn’t really want to use it.” (news.ycombinator.com).
Another commenter noted the absurdity that even figuring out which AMD cards are supported is non-trivial – one GitHub issue had been open for 2 years with users complaining the docs don’t list supported GPUs. Officially, AMD focused ROCm on data-center cards (MI series and certain Radeon Pros), but many AI enthusiasts experiment on consumer GPUs (like Radeon RX or older MI cards). Limited support there meant less grassroots adoption.
A particularly biting comment from the same HN thread: “the first thing anyone tries when dabbling in GPU AI is running llama.cpp (LLM on GPU)… yet [on AMD] it’s a cluster*** to get to work. Some ‘blessed’ cards work with proper drivers; others crash or output garbage… Then you dump it and go buy Nvidia – et voilà, stuff works first try.”* (news.ycombinator.com).
This illustrates the risk for AMD: a single bad experience can turn a potential convert back to Nvidia for good. (In this case, an AMD user replied that on his high-end Radeon VII it worked and was “rock solid”, but the original point remained – it only works on some cards/configs, not consistently).
Now, AMD is acutely aware of these perceptions and by 2025 has taken steps to improve things. High-level, AMD realized that to break Nvidia’s software moat, they must invest in developer experience heavily – something they arguably neglected while focusing on hardware. A revealing report by SemiAnalysis noted that in January 2025 AMD finally launched a formal Developer Relations team (years behind Nvidia) and adopted a “Developer First” strategy, with leadership acknowledging the gaps in ROCm (semianalysis.com).
AMD’s CEO Lisa Su herself reportedly met with external engineers who had been struggling with ROCm and gathered feedback on dozens of bugs, kicking off a “wartime mode” within AMD to fix the software. The tone internally shifted to acceptance that “our software has way more bugs than Nvidia’s” and urgency to close the gap. Concrete moves included: adding MI300 support into PyTorch’s continuous integration (so that new PyTorch releases automatically get tested on AMD GPUs), working on better documentation, and launching an AMD Developer Cloud to let anyone test AMD GPUs easily in the cloud (tomshardware.com).
By mid-2025, AMD unveiled ROCm 7.0, a significant update aimed at boosting performance and usability. AMD claims that ROCm 7 delivered 3.5× higher inference throughput and 3× training throughput on MI300X compared to ROCm 6 (measured on models like Llama 70B and DeepSeek-R1). Essentially, software optimizations alone tripled performance, which shows how much room there was for improvement.
The update also introduced support for Windows (previously ROCm was Linux-only) and even enabled consumer Radeon GPU support in some capacity – potentially letting more developers experiment on AMD without special hardware. The ROCm 7 release notes highlight better multi-GPU scaling (distributed inference with libraries like vLLM), plus support for new low-precision data types FP4/FP6 used in MI350 series.
Figure: AMD claims that its ROCm 7 software update yielded major performance gains over the previous version. In tests with large AI models (Llama 3.1-70B, Qwen-72B, and DeepSeek-R1), an MI300X system achieved 3.2× to 3.8× higher inference throughput under ROCm 7 versus ROCm 6tomshardware.com. While vendor-provided, these figures underscore how improving the software stack can unlock much more of the hardware’s potential.
Is this enough to make developers happy? Possibly not overnight, but directionally it’s positive. AMD expanding ROCm to support more GPUs (even integrated APUs) could foster a larger community. Their Dev Cloud offering 25 free hours on real MI300X hardware is an interesting carrot – essentially saying “come try our GPUs, at no cost, and see the progress.” It mimics strategies by Google (TPU Research Cloud) and could lower the barrier to entry.
However, skepticism remains. A candid line in SemiAnalysis said AMD’s progress is notable but “nowhere near keeping up with Nvidia’s pace” in software. Nvidia isn’t standing still; they continue to refine CUDA, cuDNN, and release new tools (for example, Nvidia open-sourced a distributed inference library called TensorRT-LLM (Dynamo) to ease large model serving, which AMD doesn’t yet match).
One point: Nvidia’s software stack has become very Pythonic and high-level (integrations in PyTorch, JAX, etc. are seamless), whereas a criticism of AMD was that ROCm lacked that polish. AMD is playing catch-up in user-friendliness.
Another factor is model compatibility. Many cutting-edge models or research code have CUDA-specific operations or assume an Nvidia environment. Porting them to AMD can range from trivial (if using standard ops that TensorFlow/PyTorch can handle via ROCm) to arduous (if using custom CUDA kernels or older libraries). For example, the UCL team porting AlphaFold3 to AMD MI300 noted some dependencies assumed Nvidia and had to be replaced or recompiled; they encountered a bug in AMD’s JAX that forced using a slightly older JAX version (since the newest JAX didn’t detect AMD GPUs due to an initialization bug).
They eventually got it working, but these are the kinds of “paper cuts” that early adopters face. A biotech engineer might ask: why go through that, if sticking with Nvidia avoids it? AMD’s answer must be: because it can be worth it – perhaps in cost, or performance for your specific use case, or supply availability.
Cost and Accessibility
AMD often undercuts Nvidia on price. For instance, when Nvidia’s H100 prices skyrocketed on secondary markets, AMD MI250 or MI100 cards were reportedly available at steep discounts (anecdotes floated about cloud providers picking up MI250s cheaply to offer budget GPU instances). In one analysis, AMD’s older MI100 card was cited as “the best FLOPS per dollar today” – “58 billion transistors for $999, yet nobody in ML uses it” lamented Hotz, precisely because of the software hurdle (chipstrat.com).
The Absci partnership provides a real-world check: Absci, an AI-driven biotech, said AMD’s hardware “performs exceptionally for some of our most complex AI workloads” and that AMD was eager to work together to refine and optimize their hardware for life sciences. This hints that AMD might be giving dedicated support (and perhaps discounts) to select biotech firms to prove viability. Indeed, AMD invested $20 million in Absci as part of that deal, essentially subsidizing a success story.
Absci’s CEO noted they need hardware that scales with their needs, and AMD delivered on performance and was willing to customize solutions to reduce Absci’s time to drug candidate. This kind of close partnership and cost-sharing could be attractive to other biotechs – provided AMD’s hardware truly meets their needs. Absci still hedged by not committing exclusively to AMD (genengnews.com), implying they’ll use whatever works best.
For big cloud or enterprise buyers, cost also ties to supply chain reliability. Nvidia’s backlog in 2024 made headlines; some cloud vendors literally couldn’t get enough H100s. AMD, with lower demand, may have had inventory – a dynamic possibly behind Oracle’s enthusiastic adoption of MI300-series. However, geopolitical factors complicate the picture: U.S. export controls have hit both Nvidia and AMD’s high-end chips for China. AMD’s MI250 was reported to be blocked from sale to China as well, costing AMD $800 million in potential revenue.
Nvidia responded by making slightly downgraded “China-special” versions (A800, H800); AMD would likely have to do similarly if it pursued that market. Meanwhile, Chinese alternatives (Huawei Ascend, Biren GPUs) are trying to fill the gap. The Huawei CloudMatrix cluster unveiled in 2025 used 384 Ascend 910C chips with an optical interconnect to rival Nvidia’s performance, but consumed 2.3× more power per unit performance – a brute force, less efficient approach.
This suggests that outside the Nvidia/AMD duopoly, others can compete on absolute performance only by being very power-inefficient or using many more chips, which in power/cost-constrained environments isn’t ideal. For European and other regions concerned about too much dependence on a single U.S. vendor, AMD’s rise is welcome: for example, the LUMI supercomputer in Finland (used for AI and research including life sciences) is built on AMD CPUs and GPUs entirely (amd.com).
A EuroHPC call in 2025 even specifically solicited help to port AI software to AMD GPUs on LUMI (lumi-supercomputer.eu), showing institutional support for AMD in HPC. The newly launched JUPITER exascale in Germany may also involve non-Nvidia hardware, though details are evolving (fz-juelich.de).
Real-World Adoption – Is Anyone Using AMD in Biotech? A few anecdotes beyond Absci: The University of Texas’s research computing group deployed AMD GPU servers donated by AMD, and got popular ML tools running – they report that TensorFlow, PyTorch, AlphaFold, and even molecular dynamics apps like GROMACS are installed and ready on the AMD pod, and interestingly, “AlphaFold performance is quite similar” on AMD vs Nvidia servers in their tests (cloud.wikis.utexas.edu).
This success is likely because those codes have been adapted to ROCm or at least to run via container with ROCm base. It shows that with effort, parity can be achieved in certain workloads. Another example: pharmaceutical giant GSK partnered with Cerebras (not AMD) for a specific deep learning project on gene regulation, using Cerebras’s wafer-scale engine to train models that were hard to parallelize on GPUs.
While not directly AMD, it underscores that big biopharma are willing to try alternative hardware for AI if there’s a compelling advantage (Cerebras offered the ability to train one huge model on a single wafer-scale chip). AMD’s strategy likely is to find niches like that where their 2× memory or some feature solves a problem elegantly.
For instance, consider large bio-LLMs (language models on biological sequences or literature) – if an AMD MI300X can fine-tune a 70B parameter model without needing model parallelism (because 192GB VRAM fits the model), that’s a simplicity and speed win; an Nvidia shop would need two or three 80GB GPUs working in concert to do the same, introducing extra complexity.
A senior Nvidia engineer might retort that their upcoming 144GB H100 or Blackwell GPUs even that score – but until those ship widely, AMD has a window.
Still, the mindshare belongs to Nvidia in most biotech AI circles. AMD’s foothold in actual biotech companies remains small. One telling quote from GEN’s stockwatch piece: “Last year alone, Nvidia’s computing rival Nvidia backed or partnered with at least five biotechs employing AI… AMD’s first collaboration in life sciences [Absci] comes as Nvidia has spent years expanding its footprint in the sector.” Indeed, Nvidia had deals with Recursion, Schrodinger, Peptone, and others well before AMD woke up to this market. So AMD is late, but trying to accelerate.
Energy Efficiency and Operational Factors
Power and cooling are practical considerations for any R&D lab or cloud. Nvidia’s H100 (SXM) draws ~700W at peak; AMD’s MI250 ~500W; MI300X ~600W; MI355X up to 1400W with liquid cooling. If using air-cooled enclosures, Nvidia had an advantage that its top chips could be air-cooled (with tradeoffs), whereas AMD’s might strictly need liquid. That’s fine in supercomputing centers (Frontier and El Capitan are fully liquid-cooled), but a typical biotech server room might not be ready for 1.4kW accelerators without infrastructure upgrades.
When Tom’s Hardware compared performance per watt, they noted Nvidia A100 was generally more efficient than MI250X in mixed AI workloads And Huawei’s attempt to outdo Blackwell ended up 2.3× less efficient per FLOP (tomshardware.com) – an example that chasing absolute performance can hurt efficiency. AMD will need to prove that despite higher TDP, their performance per dollar (and maybe per watt) is favorable.
Oracle’s claim of 2× price-performance on OCI hints that AMD likely gave them a very good deal and that MI355X, while power-hungry, must deliver a lot of throughput to justify itself. AMD also talks up TCO (total cost of ownership) advantages of needing fewer GPUs because each has more memory – fewer nodes can mean less overall power if the alternative is doubling the number of Nvidia GPUs to handle the same workload with smaller memory. There’s some truth there for certain use cases.
Usability and Support
Developer sentiment is slowly improving. AMD engaging directly with communities on GitHub, fixing long-standing bugs, and actually advertising what works (and what doesn’t) is building credibility. A comment on HN noted “when it works, it works well” about AMD GPUs and that he got a good deal on a Radeon VII with HBM memory – implying that for savvy users who choose supported hardware, AMD can be both fast and cost-effective (news.ycombinator.com). The problem is those conditions (“supported hardware”, “savvy user”) are narrower than Nvidia’s plug-and-play ubiquity. AMD will continue to face an uphill battle convincing risk-averse enterprise IT and scientists that they won’t lose time and productivity dealing with software snags.
The semiAnalysis (semianalysis.com) piece suggested AMD significantly boost its software engineering headcount and even hinted their compensation wasn’t competitive enough to attract top talent compared to Nvidia or AI startups.
In other words, AMD’s culture has to shift to treat software with as much importance as silicon. Their recent actions indicate this shift may be happening (the tone from Lisa Su downwards has changed to “we must fix this, whatever it takes”). But culture changes take time – whether it’s fast enough to matter in this cycle of the AI hardware race remains to be seen.
Bottom Line on AMD
For investors, AMD’s efforts in AI represent both a potential new revenue stream (leveraging their manufacturing prowess and IP) and a necessary fight to remain relevant in a data-center future increasingly centered on AI. AMD’s stock movements reflect this tug-of-war: early 2025 saw optimism with announcements like Absci, but also pessimism from analysts who see Nvidia maintaining a comfortable lead. In biotech specifically, one can interpret that AMD has not yet broken Nvidia’s dominance, but it has entered the arena. The coming 1–2 years will test if AMD can convert small beachheads (Oracle’s cloud, one or two flagship biotech wins) into broader momentum.
If AMD’s MI300/MI350 GPUs demonstrate clear real-world advantages – e.g., a pharma reports they trained a model in half the time or cost by using AMD – that would be a tipping point. Conversely, if AMD fumbles (delays, underdelivers software, etc.), the industry may simply stick with the known quantity, Nvidia, especially as Nvidia rolls out even more powerful Blackwell GPUs and its own CPU+GPU combos (which could neutralize some advantages of AMD’s platform).
In the next section, we’ll compare the CUDA vs ROCm ecosystems directly, and include more of the honest feedback from engineers in the trenches. We’ll also briefly look at the other players (Intel, TPUs, etc.) and their roles. Finally, we’ll wrap up with the market outlook and what it means for biotech innovation and investment.
CUDA vs ROCm: Ecosystem Showdown and Developer Sentiment
It is useful to directly compare the two competing software ecosystems – Nvidia’s CUDA (and associated libraries) versus AMD’s ROCm – since this is often the deciding factor in hardware adoption. One might think performance or price is king, but for many companies, developer productivity and time-to-solution are far more valuable. A GPU that is 20% cheaper is a bad deal if your team spends an extra 6 months wrangling software to use it. As one commentator put it, “they need to make using their hardware easy… fix their driver bugs… then community will come” (news.ycombinator.com).
Programming Model and Tools: CUDA is a proprietary but free-to-use programming model that has matured over 15 years. It provides a C++ API, but most AI practitioners encounter it through frameworks (PyTorch, etc.). Those frameworks rely on Nvidia’s cuDNN, cuBLAS, etc. for performance-critical operations. Nvidia has excellently optimized these – e.g., cuDNN for convolution and transformers is hand-tuned for each GPU generation. AMD’s analogous path is via ROCm’s HIP and libraries like MIOpen (for deep learning ops).
HIP allows compiling the same source code for CUDA or AMD by essentially acting as a translator – in theory, you can take a CUDA codebase and hipify it to run on AMD. In practice, this works for some projects but not others, and HIP itself can lag new CUDA features. AMD’s libraries historically were not as optimized; for instance, earlier versions of MIOpen lacked some advanced convolution algorithms, meaning slower training. AMD’s ROCm 5 and 6 made strides, and by ROCm 7 they claim near parity in many primitives.
One telling anecdote: MosaicML (now part of Databricks) did an experiment training large models on AMD MI250 vs Nvidia A100 using their software. They found they could get decent results, but noted “the max power consumption for a single MI250 is higher… But at system level, power normalized, things were closer” (databricks.com). They also highlighted needing to adjust some kernel launch settings. This suggests that with expertise, one can achieve performance on AMD, but it may require tuning that Nvidia’s ecosystem automates.
Framework Support: PyTorch is the most popular DL framework in research (including biotech ML). It does support ROCm – you can pip install torch with a ROCm version – but often only certain versions match certain ROCm releases. Nvidia support is considered “default” and gets the newest features first. TensorFlow similarly had ROCm builds but Google’s mainline development targets CPU/GPU (CUDA) and TPU primarily.
Newer frameworks like JAX had no official ROCm support until AMD stepped in to create containers; as we saw, those were behind the latest releases. This lag can be painful if a model requires a newer library feature or bugfix.
Community and Documentation
Nvidia’s forums, StackOverflow, and even general ML forums are full of Q&A for CUDA issues, because so many people use it. AMD’s ROCm has a smaller community (though growing). Documentation was pointed out as a weak spot – e.g., not clearly listing supported GPUs or how to set environment variables to get code running on consumer cards.
AMD seems to be improving docs recently, but reputation lingers. On the plus side, ROCm being open source means one can theoretically inspect and contribute. In fact, some fixes for ROCm have come from outside AMD (community patches), but expecting end-users to troubleshoot deep compiler issues is unrealistic in a production setting.
Multi-GPU and Distributed Training
Nvidia’s NCCL library for multi-GPU communication is robust and an industry standard. AMD’s counterpart, RCCL, works but earlier versions had limitations. SemiAnalysis noted that “the delta between NCCL and RCCL continues to widen” as Nvidia adds features for new network topologies, in-network computing, etc., while AMD is playing catch-up.
For biotech workloads that need to scale (say training a model on 16 GPUs), these differences matter. If RCCL has higher latency or a bug, the whole training could stall or slow. AMD did integrate with popular frameworks for distributed inference (vLLM etc.) in ROCm 7, indicating they know this is vital.
Precision and New Features: Both CUDA and ROCm now support things like BF16, TF32, FP8, etc. Nvidia often pioneers these (e.g., TF32 in A100 to make FP32 training faster with minimal code change; FP8 support in H100 with custom transformers). AMD followed by enabling FP8/FP16 and even introducing FP4/FP6 for MI300-series.
But supporting a datatype in hardware is not enough; the software has to use it. Nvidia works with frameworks to add those (e.g., PyTorch added FP8 autocast for H100). AMD will have to push similar upstream changes for FP4/FP6 usage – which could be great for inference efficiency if done. There’s no sign yet of mainstream models using FP4, but maybe in 2025 some LLM inference will.
User Sentiment – In Their Own Words
It’s instructive to directly quote or paraphrase what engineers have said:
A machine learning engineer on Hacker News, 2024: “I don’t get why [AMD] doesn’t assign a dev or two to make the poster child [LLM] work: llama.cpp… It’s the first thing people try, yet it’s a mess on AMD. Some cards just output GGGGG or crash. Then you laugh, give up, buy Nvidia, and it works.” (news.ycombinator.com). (Ouch – that highlights how a bad first impression can cost a customer.)
A reply from an AMD user: “It does work, I have it running on my Radeon VII Pro… it’s rock solid and quite fast… [but] that card has fast HBM2 memory and was on deep sale.” (news.ycombinator.com). (Translation: it can work if you have the right high-end card and likely did some setup.)
The original poster rebuttal: “You’re having luck with yours, but that doesn’t mean it’s a good place to build a community. On some cards it works, on others not. Limited support on ROCm… when it works it works well, but…” (news.ycombinator.com).
George Hotz (from his TinyCorp blog, late 2023): “There’s a great chip on the market – 24 GB, 123 TFLOPs for $999… and yet nobody in ML uses it. I promise it’s better than the chip you taped out! … If no one uses this one, why would they use yours? So why does no one use it? The software is terrible! Kernel panics in the driver… you have to run a newer Linux kernel to make it remotely stable. I’m not sure if the driver supports two cards in one machine… when I put the second card in and run an OpenCL program, half the time it kernel panics and you have to reboot. The user space isn’t better: the compiler is so bad that clpeak only gets half the max FLOPS… and that’s a contrived workload. Supposedly [ROCm] works with PyTorch, but every time I tried, it didn’t build out of the box or segfaulted or gave wrong answers. CUDA PyTorch, by contrast, I built maybe 10 times, never a single issue.” (chipstrat.com).
(This comprehensive takedown gained notoriety; AMD folks surely read it and cringed. It enumerates multiple failure points: drivers, multi-GPU, compiler inefficiency, build problems, even silent correctness issues – “wrong answers” – which is most alarming of all. No scientist wants to wonder if a result is a bug or a finding.)
On the positive side, consider Absci’s experience, a rare public biotech endorsement for AMD: “We’ve worked with AMD… their hardware performs exceptionally for some of our most complex workloads… AMD’s team was incredibly eager to work together to refine and optimize their hardware for our needs and the life sciences more broadly.” (genengnews.com)
This indicates that when AMD does engage, they can tailor solutions. Not every customer will get that white-glove treatment though (Absci had AMD’s $20M investment as extra incentive).
Another perspective: Cloud provider experiences. Azure in preview had MI100 instances at one point; Amazon offers Intel Gaudi instances for AI as a lower-cost option. If those had huge success we’d hear more by now, so presumably they are niche. Oracle’s public enthusiasm for MI300 suggests they saw an economic advantage (they claim >2× price-performance vs previous gen, and presumably better availability than Nvidia).
They even stated AMD GPUs will “offer more choice to customers as AI adoption grows” (datacenterdynamics.com), highlighting that some customers do ask for alternatives (perhaps to avoid being solely dependent on Nvidia). For instance, companies concerned about U.S. export limits might want to standardize on something the U.S. government hasn’t targeted as much (though as mentioned, high-end AMD might also be restricted similarly if it hits performance thresholds).
Other Competitors Briefly
While Nvidia and AMD are the main event, it’s worth noting Intel’s Gaudi2 (Habana Labs) has shown up in MLPerf benchmarks and on AWS, often with competitive performance in specific tasks (ResNet, etc.) at lower cost. But software adoption is even smaller than AMD’s. Google TPU v4 pods are extremely powerful (Google touts their use in AlphaFold and various genomics at Google Research), but they are basically accessible only via Google Cloud and require using TensorFlow or JAX – which many industry teams don’t prefer for custom work (PyTorch rules outside Google).
Graphcore IPUs had a collaboration with Oxford Nanopore for basecalling DNA sequences and some work on optimizing protein models, but encountered their own software issues and limited scale. Cerebras had GSK and others trying it for specific models (their whole pitch is you can avoid the complexity of GPU clusters), yet training workflows have to be rewritten to their compiler, a barrier. One could say these alternatives are like exotic sports cars – impressive in specific scenarios, but not general-purpose workhorses like GPUs.
For biotech firms without the luxury of huge engineering teams, straying from the GPU path is risky. Even Recursion, which dabbled with Graphcore IPUs at one point, ultimately partnered with Nvidia for their big systems. So the ecosystem gravity around CUDA is strong.
However, there is interest in “sovereign” AI hardware – Europe talks about it, China is forced into it. If anything, this could benefit AMD in the West (as a more open alternative) and local players in China. For example, China’s Huawei is clearly using its Ascend AI chips in healthcare (China’s hospitals and companies doing medical AI likely use Ascend for political/purchase reasons). Huawei’s latest AI chips aim to rival Nvidia’s in specs (tomshardware.com), but the verdict is that they need far more chips and power for same performance – so efficiency lags.
If Nvidia ever were completely barred from a region, AMD or others could step in but would they do any better on efficiency or support? Not immediately – it would take time to build that ecosystem.
In Table 1 below, we attempt a high-level comparison of Nvidia vs AMD offerings relevant to biotech AI as of 2025:
| Aspect | Nvidia (CUDA Ecosystem) | AMD (ROCm Ecosystem) |
|---|---|---|
| Hardware Performance (FP16/AI) | H100: ~1,000 TFLOPS FP16/BF16 (with sparsity), 80GB HBM2e (PCIe) or up to 94GB (SXM); Blackwell B100 expected ~2× Hopper’s AI performance. Excellent at small batch and latency-critical tasks (Tensor Cores, optimized scheduling). | MI300X: ~880 TFLOPS FP16 (theoretical), 192GB HBM3; MI355X: peak ~2,516 TFLOPS FP16 (or >10,000 TFLOPS FP8), 288GB HBM3eglennklockwood.com. Strong at large-batch throughput due to huge memory, but may need tuning to reach full speed. FP64 is higher than Nvidia (good for physics). |
| Power Efficiency | Generally high, but top-performance configs are power-hungry (H100 SXM ~700W). Blackwell expected to improve perf/W. Nvidia leverages 5nm and architectural efficiency; e.g. GH200 (Grace-Hopper) ties CPU+GPU to save on data movement power. MLPerf shows Nvidia leads in perf/W in many tasks. | Raw power draw is higher for peak performance. MI250X ~500W; MI300X ~600W; MI355X up to 1,400W (liquid-cooled)glennklockwood.com. Perf/W improving with 3nm CDNA4, but SemiAnalysis notes MI355X rack solutions still trail Nvidia’s in efficiencytomshardware.comtomshardware.com. Potential for better perf/$ can offset perf/W in some deployments. |
| Memory & Bandwidth | H100: 80GB (2TB/s). Blackwell B200: ~192GB HBM3e (rumored), 4+TB/s. NVLink interconnect allows sharing memory across GPUs (up to 256GB addressable in 2 GPUs etc.). | MI300X: 192GB (5.2 TB/s); MI355X: 288GB (8 TB/s)datacenterdynamics.com. Leads in single-GPU VRAM capacity (advantage for very large models). AMD Infinity Fabric links (7x links per GPU) for multi-GPU, but no equivalent of NVSwitch yet; 8-GPU OAM module allows fast intra-node comms. |
| Software Support (Frameworks) | Universal support. PyTorch, TensorFlow, JAX – all optimized for CUDA first. New model architectures typically debut with CUDA kernels. Nvidia’s libraries (cuDNN, cuBLAS, NCCL, TensorRT) integrate with frameworks and get continuous tuning. Turnkey solutions (Clara, TensorRT-LLM etc.) for domains. | Partial support. PyTorch and TensorFlow have ROCm versions, but often lag in version or features. JAX support exists via AMD’s containers but lags official releaseslinkedin.com. Fewer pre-built domain libraries (some third-party efforts for bio, but not as comprehensive as Clara). Requires more manual effort to use cutting-edge models (e.g., adapting CUDA ops to HIP). |
| Developer Experience | Generally smooth: well-documented, large community, many tutorials assume Nvidia. Debugging and profiling tools (Nsight systems, CUPTI) are robust. If an issue arises, Nvidia likely has a forum answer or update. “It just works” for most popular AI projects. | Historically rough, but improving. Documentation gaps being filled, new ROCm releases fixing bugs. Still reports of driver quirks, installation complexity (specific Linux kernels needed, etc.). AMD’s tooling exists (rocProfiler, etc.) but not as widely used. Community smaller, but open-source nature means one can contribute fixes (if highly skilled). Overall, still more friction reported than CUDAchipstrat.comnews.ycombinator.com. |
| Ecosystem & Partnerships | Extensive in biotech: collaborations with multiple biotechs (Recursion, Schrodinger, Genesis, etc.), SDKs like Clara for healthcare, validated pipelines (e.g., reference workflows for cryo-EM or genomics). Nvidia’s NVenture investments align with promoting GPU adoption in life sciencesgenengnews.com. Global presence: used by labs and companies in US, EU, Asia. | Nascent in biotech: first major partnership (Absci) in 2025genengnews.com. Pushing into cloud (Oracle OCI, etc.) with aggressive dealsdatacenterdynamics.com. Presence in academic HPC (Frontier, LUMI) means some life science research uses AMD there, but often with heavy support. Fewer dedicated life-science libraries (it relies on open-source community to port things like OpenMM, etc.). AMD courting partners now (likely more to come if Absci is success). |
Table 1: High-level comparison of Nvidia vs AMD AI platforms relevant to biotech (2025).
The table underscores that Nvidia holds the high ground in software maturity and integrated solutions, while AMD competes on raw specs like memory and is quickly patching up software gaps. The question an R&D leader might ask is: “Do I want to be adventurous and potentially reap some cost or performance benefit with AMD, or stick with the safe bet of Nvidia?”
In 2025, many still lean toward the safe bet, especially if their AI work is mission-critical (e.g., a clinical AI system where you can’t afford unpredictable behavior). But if, say, you’re running a million inferences of a screening model and it’s purely a cost play, AMD might tempt you with 2x the memory and a lower price – allowing you to do it on fewer GPUs.
Other Players and Regional Considerations
While Nvidia and AMD command the spotlight, the broader context includes other hardware players and geopolitical currents that influence who gets used where:
Intel (Habana Gaudi)
Intel’s Gaudi2 accelerators showed strong MLPerf Training results for some vision and NLP tasks at lower price points than Nvidia A100 (targeting cost-sensitive cloud customers). Amazon AWS offers Gaudi instances and claims up to 40% cost savings for training some models. However, developer uptake is limited – you have to use Habana’s graph compiler, which is an extra learning curve, and model porting is non-trivial. For biotech, hardly any literature or user stories mention Gaudi, implying minimal traction so far.
Intel is working on Falcon Shores (future chip mixing CPU+GPU cores for HPC/AI) but that’s a 2026 story. If one is extremely cost-focused and doing something like training a smaller CNN or running batch inference, Gaudi could be an option, but for large complex models it’s not mainstream.
Google TPUs
Google’s TPUs (currently v4) are very powerful (each v4 board can deliver >100 TFLOPS in BF16, and pods of 4096 TPUs have achieved top results). DeepMind likely leveraged TPUs for large AlphaFold training runs internally. Google Cloud does let outside users access TPUs, and some academic groups used TPU pods for genomics and protein models.
But using TPUs means using TensorFlow or JAX, which not all industry teams are comfortable with (PyTorch has become the standard outside Google). Also TPUs can’t be bought, only rented on GCP. So TPUs remain a niche – great if you’re in the Google ecosystem (e.g., some top universities or consortia collaborating with Google), otherwise not much impact on the average biotech company, which is more likely on AWS/Azure/On-prem with GPUs.
Graphcore IPUs
U.K.-based Graphcore’s IPU is a unique architecture with many small cores and on-chip memory, excelling at fine-grained parallelism. They achieved some success in showing faster training for certain models like graph neural networks and had a collaboration to accelerate Oxford Nanopore’s sequencing basecalling. They also targeted protein interaction networks and such.
However, writing or adapting code to IPUs requires using their Poplar SDK and often re-thinking algorithms for their mesh. A few research papers in bio have tried IPUs, but it’s far from displacing GPUs for general use. Graphcore’s future is uncertain as they face stiff competition and have had layoffs. Unless a specific bio application perfectly matches IPU strengths (and the team is willing to rewrite for it), IPUs are a hard sell.
Cerebras (Wafer-Scale Engine)
Cerebras put a massive 850,000 cores on one silicon wafer, targeting large dense models that normally would need many GPUs. GSK’s AI team used a Cerebras CS-2 system to train an epigenetic model (predict gene regulation) and reported it allowed training on full genomes without splitting data, a novel capability. For certain large models where inter-GPU communication is a bottleneck, Cerebras offers a potentially simpler solution (no need to distribute across GPUs, just one big chip). They’ve also been used for some protein and chemistry models and even have partnerships with biotech research centers.
The downsides are the cost (millions per system), and you must use Cerebras’ software stack and compiler – meaning some work to port models (though they support PyTorch via their framework to some degree). Cerebras remains a niche, but one to watch if some biotech finds it dramatically speeds up a key workload (like virtual screening or antibody design models). So far, no public claim of “we found a drug twice as fast because of Cerebras” exists, so it’s exploratory.
Domestic Chinese chips (Huawei, Biren, etc.)
As mentioned, China’s need to replace Nvidia has led to big efforts. Huawei’s Ascend 910 (used in the CloudMatrix system) and newer Ascend 920 aim to be on par with high-end GPUs. Huawei even developed their own AI frameworks (MindSpore) and optimized AI applications like medical image analysis for Ascend. Chinese cloud providers (Alibaba, Tencent) have their own chips too (Alibaba’s Hanguang). But these largely serve the Chinese market.
If we talk global biotech, a Western pharma is not likely to use a Huawei cluster anytime soon for IP/security reasons. Chinese biotech companies, on the other hand, will use domestic hardware if they can’t get enough Nvidia GPUs. We saw that Chinese systems can achieve high performance but often at cost of efficiency (tomshardware.com). China’s long-term goal is to become self-reliant, so by late decade we might see more competitive Chinese AI chips, but currently they are a generation or two behind Nvidia and AMD in tech (partly due to sanctions on cutting-edge fabrication). For example, Biren BR100 was a promising startup GPU, but US sanctions cut them off from advanced fab, hampering progress.
Regional Market Dynamics
United States
Here Nvidia is deeply entrenched (all the major cloud providers are headquartered in US, and most AI-first biotech startups are using Nvidia by default). The US government also pours money into Nvidia-powered supercomputers for biomedical research (like NIH’s Biowulf cluster uses lots of Nvidias). AMD being a US company too means it can compete freely; it’s actually a selling point for the US government to have a second source (for resilience). The Frontier and upcoming El Capitan exascale systems (both in US national labs) are fully AMD – those will be used for some life science simulations and AI for sure, giving AMD a showcase.
If AMD wants to boost adoption, catering to federal initiatives (like DOE or NSF grants for AI in healthcare that could specify using AMD resources) might help. But private sector in US will go with whatever is easiest – currently Nvidia. We did see Microsoft test AMD GPUs for OpenAI workloads, but apparently they weren’t impressed and didn’t follow up with big orders (semianalysis.com). However, by H2 2025, if AMD’s improvements bear fruit, companies like Microsoft or OpenAI might reconsider to avoid overdependence on Nvidia (OpenAI reportedly has interest via Oracle’s AMD cluster).
Europe
Europe has been keen on technological sovereignty. The EuroHPC Joint Undertaking funded several AMD-powered supercomputers (LUMI, etc.) and at one point Europe’s EPI project even considered making GPUs (though that pivoted to RISC-V accelerators). European pharma and biotech could be more open to AMD if it aligns with EU initiatives for openness and avoiding lock-in. Also, power costs in Europe are high, so efficiency matters – Nvidia currently likely wins there, but if AMD’s MI300X uses a bit more power but you need half as many GPUs thanks to its memory, the math could favor AMD in some cases.
Some European research consortia are actively porting software to AMD (e.g., a EuroHPC Centre of Excellence might take popular bioinformatics GPU codes and ensure they work on AMD). This could gradually improve things. Companies like Siemens Healthineers (medical imaging) or SAP (doing some AI for healthcare) might also test AMD to keep Nvidia pricing honest.
Japan
Japan’s big flagship supercomputer Fugaku used ARM CPUs and no GPUs, focusing on vector engines – a unique path. But for AI, Japan has also built GPU clusters (the ABCI AI supercomputer uses Nvidia V100s, and new systems like Tsubame at Tokyo Tech have A100s). Japan’s preferred vendor for big systems has been Fujitsu (for CPUs) and they partner with either Nvidia or AMD for GPUs. There is talk of Japan possibly considering AMD GPUs for a future system, but Nvidia has a presence (Nvidia opened an AI center in Kyoto, etc.).
Japanese pharma tends to use whatever the global standard is (mostly Nvidia currently). One interesting twist: Japan (and Asia in general) have a lot of developers contributing to PyTorch and other frameworks – if some of them focus on improving ROCm support (maybe funded by government projects), it could accelerate global adoption.
Rest of World
In India, Africa, Latin America, cost is a big factor. Cheaper alternatives (AMD, or even second-hand GPUs) might be appealing for research groups. AMD’s open approach could resonate with countries that don’t want to rely on a single US corporation’s closed ecosystem. On the other hand, Nvidia has been good at providing grants and discounts to researchers globally (like Nvidia’s GPU grant program for AI researchers). AMD may need to do more of that (donating those servers to UT Austin was one example (cloud.wikis.utexas.edu), they should do more such seeding in universities worldwide so new students learn AMD as well as CUDA).
Investment and Industry Implications
For investors in the semiconductor or biotech space, the dynamics between Nvidia and AMD in 2025 carry significant implications:
Nvidia’s AI dominance = Pricing Power
Nvidia’s near-monopoly in high-end AI GPUs has allowed it to command premium pricing and enjoy huge margins. For biotech companies, this means AI compute is a costly capital expense or cloud expense line item. If Nvidia remains unchallenged, one should expect those costs to stay high (good for NVDA stock, less good for cost-conscious biotechs). If AMD or others start cutting in, we could see price competition or at least negotiation leverage for buyers.
Already, some cloud providers (Oracle) are using AMD-based offerings to undercut rivals on price for AI training instances. This could pressure AWS/Azure to also consider AMD to avoid losing customers who balk at Nvidia instance prices. In turn, if Nvidia senses demand shifting, it might adjust pricing or release more mid-range offerings to cover the lower end.
Watch the Software Moat
As an investor, one might keep an eye on qualitative signals: Are developers saying “hey, ROCm is pretty good now”? Are major AI frameworks merging more AMD-optimized code? The ChipStrat analysis noted “AMD has finally understood that developers… made Nvidia’s success” (chipstrat.com).
If AMD can execute on that understanding, it could slowly erode Nvidia’s moat. Conversely, if AMD stumbles or delays ROCm improvements, Nvidia’s moat gets even stronger (especially as Nvidia starts to integrate more software and cloud services into its offering – e.g. DGX Cloud partnerships mean renting Nvidia GPUs with Nvidia’s full stack ready to go, which many enterprises might prefer to tinkering themselves).
Biotech Compute Demand is Soaring
Regardless of which vendor wins, the overall demand from biotech for AI compute is rising. Pharma giants are now doing internal models that rival smaller tech companies’ efforts. Every big pharma has an “AI in R&D” program, often requiring hundreds of GPUs for tasks from target discovery to automated image analysis in pathology. Startups in AI drug discovery raised a lot of capital in recent years and spend a good chunk of it on compute (some literally mention “we will use funds to scale model training”).
This means the TAM (total addressable market) for AI hardware in life sciences is growing, benefiting whoever supplies that hardware. If AMD manages to get, say, a 30% share of new deployments by 2026, that could be hundreds of millions in revenue in a market Nvidia once had nearly 100% of. On the flip side, if Nvidia stays above ~90% share in this niche, they effectively have a lock on a growing annuity.
Risk of Lock-In for Biotech
From the perspective of a biotech executive (not the chip investor), relying solely on Nvidia could be a strategic risk – akin to relying on a sole supplier. What if Nvidia faces shortages (like in 2024) or dramatically raises prices? That could slow R&D. So some diversification is healthy. It’s analogous to how biotechs think about supply of reagents or other critical inputs. Thus, even if AMD isn’t quite equal, some firms might support it to nurture an alternative.
This dynamic is somewhat like the early days of x86 vs alternative processors – eventually the cheaper viable alternative gained enough traction to balance the market. We might see consortiums or industry groups promoting open solutions (e.g., OpenACC, SYCL, or other cross-platform languages) to ensure code can run on multiple backends. That is a possible hedge against Nvidia lock-in – if developers write in a portable manner, switching GPU vendor becomes easier. Today though, most write in CUDA directly or use libraries that are CUDA-only, reinforcing lock-in.
Timeline – Patience Required
For AMD investors, one must recognize that breaking a decade of Nvidia’s lead will not happen overnight. Even if AMD had the best chip today, changing developer habits and re-tooling codebases takes time. The scenario might be: in 2025 AMD makes small gains (via Oracle cloud, a few showcase wins like Absci), in 2026 their next-gen MI400 narrows hardware gaps further and more software is stabilized, and maybe by 2027 we see a more even playing field. SemiAnalysis speculated AMD’s real chance to fully catch up might open in H2 2026 when they launch a true rack-scale solution (MI450X with 128-gpu fabric) to compete with Nvidia’s own rack-scale offerings.
If that holds, then for the next year or two Nvidia can still enjoy near-prime status, but beyond that, the competition could heat up significantly. For biotech planning long-term, it means preparing for a multi-platform world could be wise (e.g., ensure your code isn’t too hardwired to one GPU brand’s quirks).
Dry Irony – “Who needs competition?”
There’s a tongue-in-cheek view among some scientists: We actually wouldn’t mind if AMD succeeds – maybe then we could afford more compute and do more science. An entire industry’s pace of innovation partially hinges on one company’s GPUs available in sufficient quantity. If AMD’s presence means faster turnaround for AI experiments (no more waiting 3 months for a server order to be fulfilled, or paying triple price on eBay for a GPU), that accelerates biotech timelines.
Conversely, if AMD flops and Nvidia can’t keep up with explosive demand, we may see a compute bottleneck slowing progress in areas like AI-driven personalized medicine or massive genomics projects. It’s a reminder that competition in this infrastructure layer has downstream effects on how quickly new therapies or discoveries reach patients.
It is somewhat poetic that in an industry (biotech) defined by intense competition for new cures, the tools enabling those breakthroughs have been monopolized by one supplier clad in a leather jacket. AMD’s effort to break the monopoly might be seen as altruistic – “liberating the scientists from Jensen’s kingdom” – or simply opportunistic business. Either way, the coming chapters of this GPU saga will influence how efficiently biotech can harness AI.
An investor might quip that Nvidia currently sells the picks and shovels in the biotech gold rush, while AMD is the newcomer at the mining camp offering a cheaper, if rough-hewn, shovel. Those who profit in a gold rush, as history shows, are often the ones selling the tools. So the question is: will there be two blacksmiths in town, or will the old one maintain a forge monopoly?
Conclusion
By late 2025, the landscape of AI infrastructure in healthcare and biotech is at an inflection point. Nvidia remains the undisputed leader, its GPUs powering everything from drug discovery startups in San Francisco, to hospital AI systems in New York, to genomics labs in London and autonomous labs in Tokyo. Its end-to-end ecosystem – high-performance hardware, a rich software stack, deep industry integrations – gives it a resilient stronghold.
For many biotech AI teams, Nvidia is the safe and obvious choice: it delivers results with minimal hassle, letting scientists focus on science rather than porting code. As one biotech engineer succinctly put it, “We chose Nvidia because we just needed it to work out-of-the-box – we don’t have the bandwidth to debug GPU software”. That sentiment has been Nvidia’s moat.
However, AMD’s campaign in 2025 has injected a dose of competition that did not exist a few years ago. AMD’s latest Instinct GPUs show technical merit – blistering throughput, huge memory, and credible performance in early tests. More importantly, AMD is finally tackling the software usability issues that long plagued it, acknowledging past mistakes and rallying to fix them.
We see ROCm steadily improving, developers starting to report success stories (even if still fewer than complaints), and major platforms like PyTorch beginning to treat AMD as a first-class citizen. It’s a reversal from the years when ROCm felt like an afterthought. AMD’s willingness to partner closely (even invest money, as with Absci) and potentially undercut on pricing or provide cloud access, makes it a compelling option for the bold. A biotech firm with heavy computing needs and a savvy engineering team might do well to pilot some AMD-based workflows – the cost savings or performance for certain large problems could give them a competitive edge.
On the other hand, firms without strong in-house computing expertise might still view AMD as “bleeding edge” and stick to the comfort of CUDA.
In truth, Nvidia’s dominance in biotech AI infrastructure is not broken in 2025 – but it is no longer absolute. There are cracks in the castle walls, even if the citadel stands firm. AMD has positioned its trebuchets (MI300X GPUs) to exploit those cracks – e.g. more memory to counter Nvidia’s smaller memory, open software to counter Nvidia’s proprietary lock, aggressive pricing to counter Nvidia’s premium – and the battle will continue into 2026 and beyond.
For the biotech industry, a more competitive hardware market is likely a boon: it can mean lower costs, faster innovation, and less risk of supply hiccups. Already, the effect is visible: cloud providers touting AMD GPU instances are forcing Nvidia-aligned clouds to adjust offerings (perhaps providing more memory per GPU instance, or offering long-term discounts) to keep customers.
We must temper enthusiasm with realism: AMD has a history of promising big and delivering late. If there’s a stumble – say MI300 yields are poor, or ROCm 8 slips a year – Nvidia could deepen its lead (especially with Blackwell and Grace processor synergy coming). Conversely, Nvidia faces its own challenges: it must keep a massive software ecosystem satisfied and continue to innovate hardware at the breakneck pace AI growth demands. Should Nvidia falter (for example, if Blackwell was delayed or underwhelming, or if a major vulnerability emerged in CUDA), AMD (or even a third player) could leapfrog in specific niches.
In the next 18–24 months, a likely scenario is coexistence: Nvidia remains the primary choice for most biotech AI tasks, especially prototyping and smaller-scale deployments, while AMD carves out a secondary role in large-scale training or specialized deployments where its memory or TCO advantages shine. Developers might write code that can run on both (using frameworks’ abstractions), giving organizations flexibility to use either hardware depending on price and availability.
This dual-vendor strategy could become the norm in big pharma IT departments: much like companies use both Intel and AMD CPUs in data centers to balance price/performance, they may use both Nvidia and AMD GPUs for AI workloads.
In a whimsical sense, one might imagine a future issue of The Economist describing how the race for cures was accelerated not just by brilliant algorithms, but also by a silicon arms race between chip giants. The dry observation might be made that drug discovery has become as much a test of Jensen’s GPUs vs. Lisa’s GPUs as of one scientist’s hypothesis vs. another’s – with a wry footnote that at least the rivalry is making the accountants slightly happier.
For the patients awaiting new treatments, they likely care little whose logo is on the AI hardware that helped find the cure – but they will benefit from the faster progress that healthy competition can bring. In that sense, the biotech industry should root for a strong AMD showing, if only to keep Nvidia on its toes and GPUs on its shelves.
As 2025 closes, the message is clear: Nvidia still rules the biotech AI kingdom, but AMD is no longer content to be an outsider – it has entered the court, bearing powerful gifts and asking difficult questions. The incumbency vs insurgency dynamic will make the coming years very interesting. Investors should watch the space closely – not just who wins in performance, but who wins the hearts and minds of developers, because in the end, that will determine whose chips run the labs of the future.
For now, many in biotech will continue buying Nvidia – but perhaps with a glance over the shoulder at AMD, and a quiet hope that a true two-horse race emerges, so that they, the users, ultimately come out ahead.
Member discussion