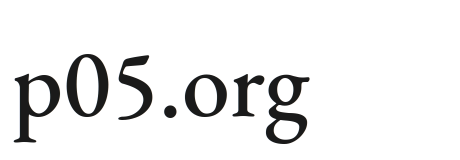
Grounding the Machine: How AI Drug Design Actually Handles Hallucination
A generative model does not know what it does not know. When it proposes a molecule, a binding pose, or a mechanism, the practical question, for anyone reading its output or underwriting the platform that produced it, is whether the answer is real or a confident fiction.

The buzz says AI designs drugs. The honest version is narrower and more interesting: AI proposes drugs, very fast and very cheaply, and an elaborate apparatus of filters, physics, and wet-lab assays decides which proposals are real.
The interesting fact about 2026 is not that hallucination was solved. It was not. It is that the industry stopped pretending the model needs to be right, and built that apparatus around the assumption that it will frequently be wrong.
The apparatus has a number attached. Insilico Medicine's rentosertib, the first molecule with both its target and its structure derived by generative AI to post a positive randomised Phase IIa result, reached its clinical candidate after synthesising only a few dozen compounds. The model proposed, cheap filters and the wet lab disposed, and the win was enrichment of the hit rate, not perfection of any single prediction.
This piece is written for clinicians, scientists, and investors who keep hearing that AI designs drugs and want to know, concretely, what stops the machine from hallucinating its way into a Phase II failure.
What hallucination means once it leaves the chatbot
The word arrived from natural-language processing, where it denotes fluent text that is confident and false. In chemistry it now describes the same failure wearing different clothes: an error the model produces itself, by filling a gap in its knowledge with something plausible rather than something true.

It shows up in two registers, and they share one cause.
| Register | How it manifests | Primary control |
|---|---|---|
| Language layer | Fabricated citations, invented mechanisms, false binding claims, fluent prose with low factual consistency | Retrieval grounding, knowledge graphs, citation verification, human review |
| Molecular layer | Invalid molecular strings, unsynthesizable molecules, physically impossible binding poses, reward hacking of the scoring function | Validity-guaranteed encodings, synthesizability and physical-validity filters, wet-lab assays |
| Shared root cause | A strong interpolator inside its training distribution; an unreliable extrapolator outside it, with no native signal of which regime it is in | Uncertainty quantification plus a workflow that screens low-confidence outputs |
A 2025 chemistry-specific benchmark, Mol-Hallu, made the language-layer problem measurable: asked to describe molecules, the models it tested deviated extensively from curated references.
Everything that follows is either a way to force the missing confidence signal or a way to backstop its absence.
Structure prediction: the model that grades its own confidence
The AlphaFold lineage is the right place to begin, because it is the one part of the stack where the uncertainty signal is built into the product and used, daily, to decide what to trust.
The models emit confidence scores with every prediction. The per-residue pLDDT flags locally unreliable regions. The predicted aligned error captures confidence in how domains and chains sit relative to one another, which tells you whether a predicted interaction is believable. pTM and ipTM give global and interface confidence.
These scores are genuine uncertainty quantification, and they work. They are also imperfect in the way that matters most, and the recent literature is blunt about it.
On dynamics. The models predict a single static structure for proteins that exist as conformational ensembles. A February 2025 paper in Nature Communications examined AlphaFold's representation of disordered-protein ensembles and found it far more limited than a single confident structure implies.
On reasoning. Chakravarty and colleagues showed that AlphaFold's predictions of fold-switching proteins are driven by structural memorisation, not learned energetics. The model is recalling, not reasoning, and it recalls badly for sequences unlike anything it has seen.
On affinity. The newest co-folding models claim to predict not just structure but binding strength. Boltz-2, released by MIT and Recursion in mid-2025, is the first to approach free-energy-perturbation accuracy at up to a thousand times the speed. But a March 2026 reliability study, On the Reliability of AI Methods in Drug Discovery, found Boltz-2's affinity predictions largely insensitive to structural accuracy, with the correlation collapsing precisely when ranking the closely-spaced top compounds that lead optimisation actually cares about.
The models, compared on the metrics that matter for drug design:
| Model | Confidence signal | Ligand-pose / affinity benchmark | Known limitation |
|---|---|---|---|
| AlphaFold3 | pLDDT, PAE, pTM/ipTM | 76.4% on PoseBusters ligand set | Chirality not always respected; degrades on novel ligands |
| Chai-1 | Per-token confidence | Comparable pose accuracy; better on unseen complexes | Still misses on truly novel chemistries |
| Boltz-2 | Confidence plus affinity head | Near-FEP on benchmarks, ~1000x faster | Affinity insensitive to structure; lags AlphaFold3 on antibodies |
Sources: AlphaFold3, Nature (2024); docking assessment, Nature Machine Intelligence (2025); Boltz-2 reliability, arXiv (2026).
The tools built to catch structural hallucination
A whole class of software exists only to catch these failures. PoseBusters, in Chemical Science, runs a battery of physical checks, bond lengths and angles, planarity, stereochemistry, steric clashes. Its central finding has been internalised by the field: deep-learning docking methods frequently fail to produce physically valid poses, and on the harder benchmark a classical tool such as AutoDock Vina can beat them once physical plausibility is actually required.
AlphaFold3's developers responded by writing a chirality penalty into the model's ranking, specifically to suppress the violations PoseBusters surfaced. A companion tool, PoseCheck, extends the scrutiny to generative models and finds that the routine habit of redocking a generated molecule can mask the very nonphysical features that should disqualify it.
The lesson generalises: a model's confidence score is necessary but not sufficient, so the field layers an independent physical check on top of the model's self-assessment.
Generative chemistry: how the model is stopped from producing nonsense
No serious platform trusts a generative model to be correct. It wraps the model in a descending stack of filters, most of them cheap, arranged so that the one genuinely expensive step, synthesis, is reached only by molecules that survived everything above it.
Each layer catches a different class of hallucination, at a different cost, and each has a blind spot the next layer must cover.
| Filter | Catches | Cost | Blind spot |
|---|---|---|---|
| SELFIES encoding | Syntactically invalid molecules (by construction) | Negligible | Says nothing about whether the molecule is good |
| Synthetic-accessibility / retrosynthesis | Molecules with no plausible synthetic route | Cheap, in silico | A route can exist and still be impractical |
| PoseBusters / PoseCheck | Physically impossible poses, steric clashes, strain | Cheap, in silico | A valid pose can still be the wrong pose |
| Docking / affinity rescoring | Weak or implausible binders | Moderate | Surrogate scores are gameable (reward hacking) |
| Wet-lab assay | Molecules that do not actually bind or are not selective | Expensive | Cannot tell you the target was the wrong target |
Validity by construction. SELFIES is a molecular string encoding in which every syntactically valid string decodes to a chemically valid molecule, removing an entire category of hallucination that the older SMILES notation permits. The guarantee is real but partial: a 2025 study found that language models can paradoxically produce worse molecules in SELFIES than in SMILES. Validity is necessary, not sufficient.
The benchmark numbers are good, and that is the trap. On the standard GuacaMol and MOSES benchmarks, modern generators routinely report validity, uniqueness, and novelty in the high nineties; a representative 2025 model, VeGA, reports 96.6% validity and 93.6% novelty. But a 2025 JCIM benchmark of 3D structure-based generators found the opposite where it counts, that deep-learning methods fail to generate structurally valid molecules and 3D conformations while classical combinatorial methods generate molecules prone to failing 2D filters. Two-dimensional validity is nearly solved; three-dimensional physical validity is not.
Reward hacking, and why multiplicity defends against it. Reinforcement learning optimises whatever proxy it is given, so it will exploit a scoring function's blind spots. The defence is multiplicity: a generator coupled to many independent scoring modules is far less able to game all of them at once than any one, and medicinal-chemistry filters and human review catch the residue. Reward hacking is not eliminated. It is made expensive to get away with.
The closed loop is the deepest control. The design-make-test-analyse cycle, run with active learning, feeds wet-lab results back into the model so each iteration is re-anchored to measured reality. This is where "we test everything" becomes literally true. The candid answer to how much hallucination is caught before versus after synthesis: the cheap, physical, syntactic failures are caught before; whether a molecule actually binds and is selective is mostly confirmed after, in assays. Rentosertib's handful of synthesised compounds is the strongest public evidence that the upstream filtering genuinely enriches the downstream hit rate.
Lilly's wager: federated learning as a hallucination control nobody calls one
The most consequential development of 2026 addresses the root cause directly. The model hallucinates most where its training data is thinnest, and the richest data in the industry is locked inside competitors who will never pool it.
In September 2025, Eli Lilly launched TuneLab, a platform giving selected biotechs access to models trained on what Lilly estimates is over a billion dollars of its own disposition, safety, and preclinical data, across hundreds of thousands of molecules. The mechanism is the point.
TuneLab uses federated learning. A biotech runs Lilly's models on its own proprietary data, inside its own infrastructure, and sends back only the resulting model updates, never the raw compounds. Lilly aggregates those updates and redistributes an improved model, so every participant benefits without anyone exposing their chemistry, with the federated plumbing built on NVIDIA's FLARE framework.
Why is this a hallucination control? Because a model's applicability domain, the region of chemical space where its predictions are trustworthy rather than hallucinated, expands directly with the diversity of its training data. A model that has only seen one company's chemistry confidently mispredicts everything outside it. Federated learning widens that domain without anyone surrendering trade secrets.
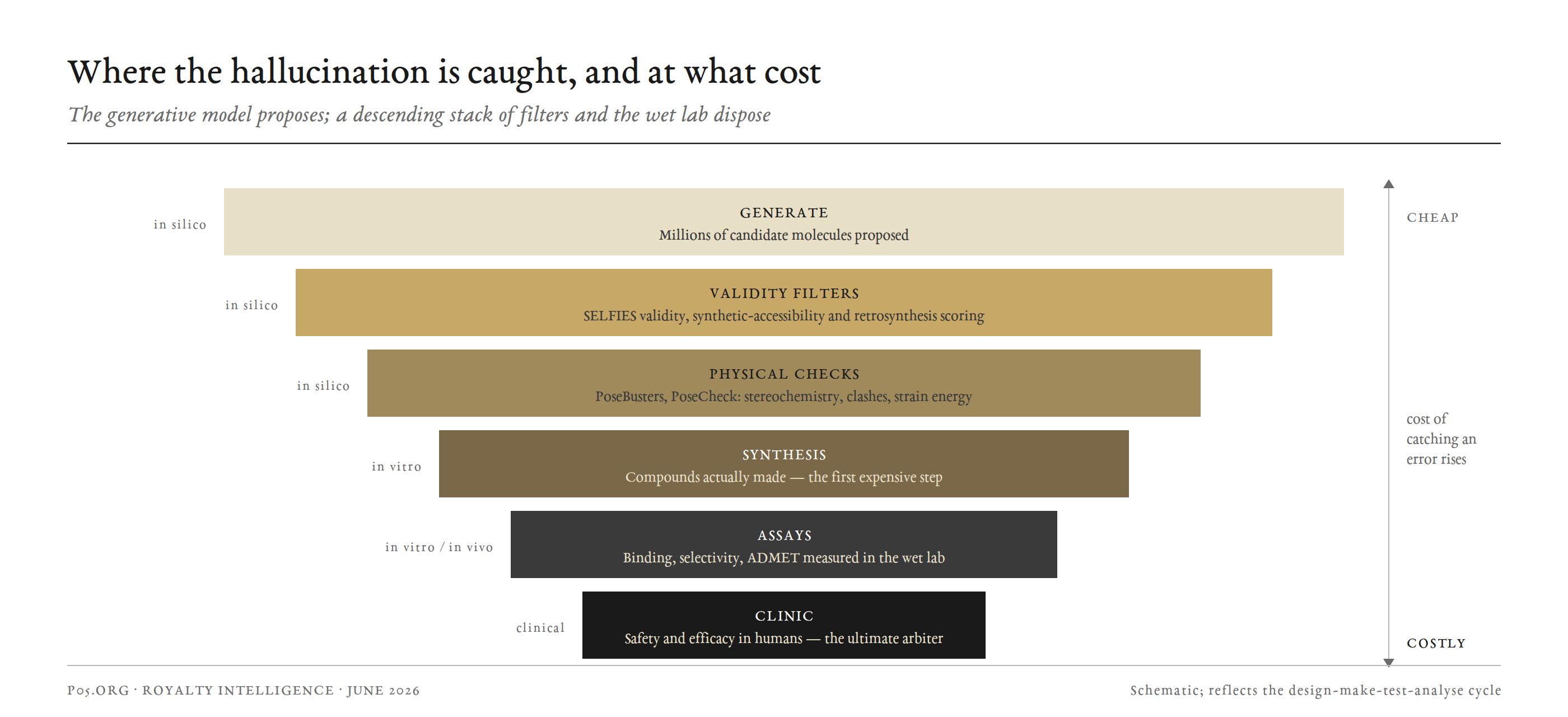
The precedent is the most underappreciated result in the field. The European MELLODDY consortium (2019 to 2022, ten pharma companies including Amgen, AstraZeneca, Bayer, GSK, Janssen, and Novartis) trained across more than 2.6 billion confidential measurements on 21 million molecules, sharing only encrypted gradients.
What matters here is how MELLODDY measured success: by conformal efficiency, the fraction of chemical space where a prediction carries low, statistically guaranteed uncertainty. Partners reported a median increase of 5.5%, with gains up to 9.7%. In plain terms, federation across competitors measurably extended the region where the models were not hallucinating.
Lilly turned that academic result into commercial infrastructure, and in January 2026 deepened the bet, announcing with NVIDIA a co-innovation lab with up to a billion dollars committed over five years on the BioNeMo platform. The strategic read: the largest holder of high-quality pharmaceutical data has concluded that the best defence against hallucination is more, and more diverse, data, gathered through an architecture that lets rivals contribute without trusting one another.
The validation funnel, and the failure it cannot prevent
Step back and the architecture of the whole field is a funnel, and the funnel is the hallucination control. Generation feeds cheap in-silico filters, which feed synthesis, then assays, then the clinic, each stage more expensive to fail than the last. The model's job is not to be right. It is to enrich the population entering the funnel so that more of what survives is real.
The disclosed numbers support that framing and also mark its hard limit.
The proof of concept. Rentosertib, Insilico's TNIK inhibitor for idiopathic pulmonary fibrosis, posted its Phase IIa result in Nature Medicine: in the 60mg once-daily arm, mean forced vital capacity rose 98.4mL against a 20.3mL decline on placebo over twelve weeks, in a 71-patient randomised trial. Both target and molecule were AI-derived, which is what makes it the first genuine clinical proof of concept for end-to-end AI discovery.
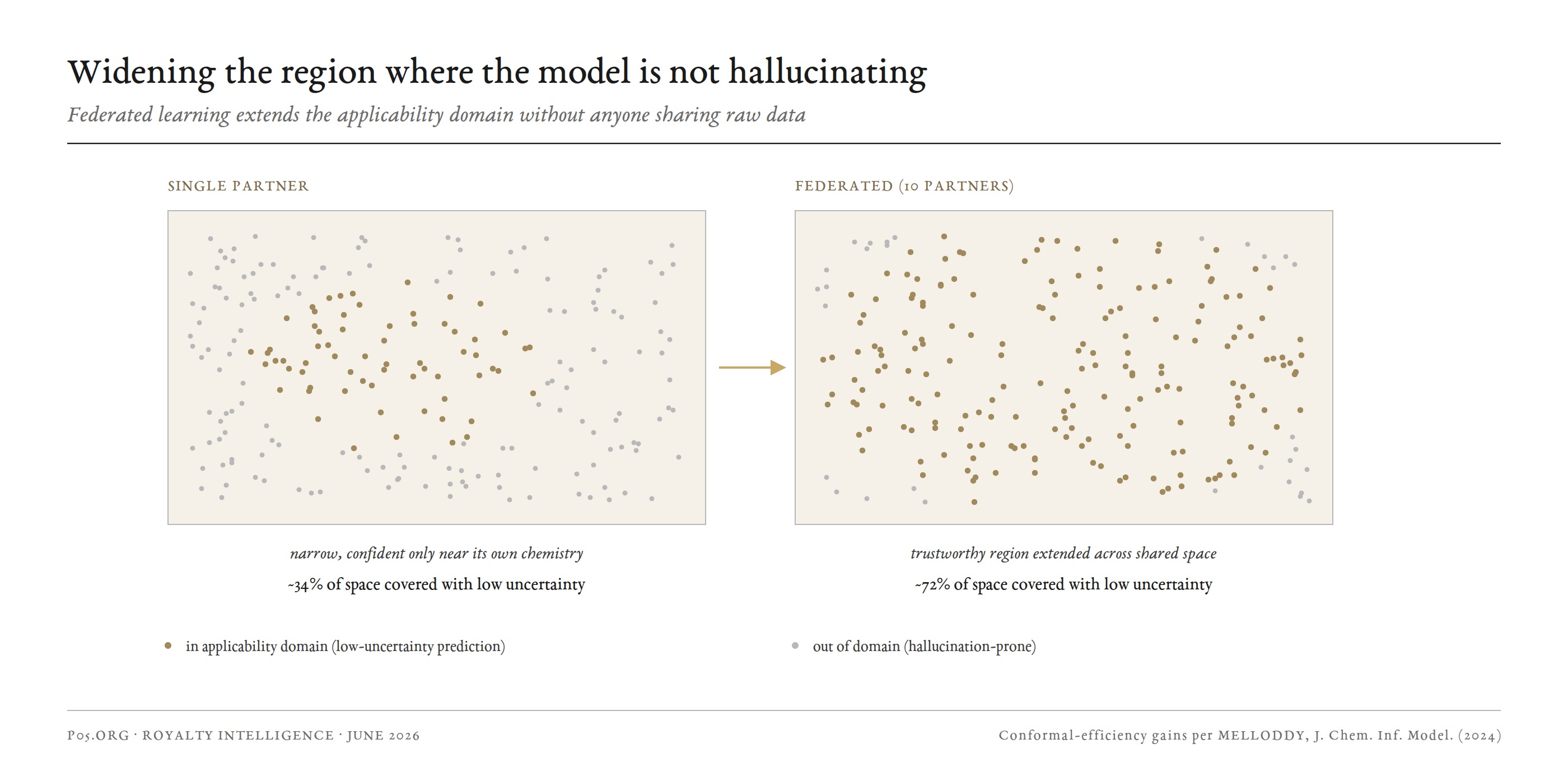
The asymmetry that defines the ceiling. The most-cited analysis, by Jayatunga and colleagues in Drug Discovery Today, found AI-discovered molecules clearing Phase I at 80 to 90%, far above the historical norm, but clearing Phase II at roughly 40%, in line with history.
The asymmetry is the whole argument. AI is good at the chemistry problem, producing molecules safe and drug-like enough to pass Phase I. It has barely moved the biology problem, whether modulating the chosen target actually treats the disease. The industry's own 2026 commentary calls the year ahead validation and disappointment in roughly equal measure.
The clinical scorecard makes the boundary concrete.
| Asset / company | Status | What it tells us |
|---|---|---|
| Rentosertib (Insilico) | Positive Phase IIa, Nature Medicine 2025 | End-to-end AI discovery can produce a real efficacy signal |
| BEN-2293 (BenevolentAI) | Met safety, missed efficacy in Phase II | A knowledge-graph target can still be the wrong target |
| DSP-1181 (Exscientia) | Discontinued in Phase I | First "AI-designed drug in trials" was not a clinical win |
| Multiple (Recursion) | Programmes paused / cut in 2025 | Scale and a clean platform do not insulate from biology |
None of these failures was a chemistry hallucination that slipped through a filter. Each was a biological hypothesis that was simply wrong, and no validity check or pose buster addresses that.
A caution from the cleanest test. The 2025 ASAP-Polaris-OpenADMET blind challenge, predicting against genuinely undisclosed antiviral data, found that for potency, classical methods remained competitive and large-scale generic pretraining bought surprisingly little. Deep learning won clearly only on ADMET. On hard, blinded, real-world tasks, the established physics-based methods still hold their ground.
The text layer and the uncertainty toolkit
When the model is a language model rather than a molecular one, the philosophy is identical, ground the output in something external and verifiable, but the tools differ.
Retrieval and knowledge graphs. Retrieval-augmented generation forces the model to answer from retrieved primary documents rather than its parameters. Knowledge graphs anchor hypothesis generation to a curated web of relationships among diseases, genes, proteins, and drugs. The BenevolentAI outcome is the necessary asterisk: grounding improved the traceability of the hypothesis without making the underlying biology correct.
Domain models, and their benchmarks. Google's TxGemma, released in 2025 and fine-tuned on millions of therapeutic examples, is the most prominent open effort. But the medical-hallucination benchmarks that accompanied it, including MedHallu, show accuracy degrading sharply as clinical context grows complex, and that retrieval can even hurt when a model struggles to reconcile retrieved facts with its own priors.
Uncertainty quantification is the rigorous answer. The cleanest reply to "how do you know when the model is hallucinating" is conformal prediction, which wraps any model and produces prediction sets with a distribution-free coverage guarantee, provided the data is exchangeable. It is no accident that MELLODDY chose conformal efficiency as its yardstick.
The caveat is the one the conformal literature itself stresses: the guarantee holds under exchangeability and degrades under the distribution shift that defines genuine discovery, exactly the regime where hallucination is most likely and most costly. This is why Lilly's data-widening and the uncertainty toolkit are two halves of one idea: enlarge the region of exchangeability, then quantify honestly where it ends.
This framing, that a workflow can convert hallucination from an unmanageable threat into bounded risk only in a theoretically mature domain, is argued at length by Rathkopf in Hallucination, reliability, and the role of generative AI in science (revised January 2026), and it matches what the empirical benchmarks above keep showing.
The regulator is arriving to match. The FDA's first draft guidance on AI in drug development (January 2025) is built around a risk-based credibility framework keyed to a model's specific context of use, with final guidance signalled for 2026 and joined by a set of FDA-EMA guiding principles in January 2026. The regulatory posture mirrors the scientific one: trust is a function of demonstrated, context-specific credibility, not of the model's confidence in itself.
The investment lens, in two directions
For anyone allocating capital, the hallucination problem cuts twice: it governs which platforms are real, and whether the AI tools used to do the diligence can themselves be trusted.
Which platforms are real
The market matured through 2025 and 2026, away from platform promises and toward clinical specificity.
| Platform | 2025-26 milestone | Wet lab? | Clinical proof |
|---|---|---|---|
| Isomorphic Labs | $2.1bn round (2026); Lilly and Novartis target deals | No (synthetic data, algorithms) | None yet; first human trials targeted ~end-2026 |
| Insilico Medicine | Largest HK biotech IPO of 2025; $2.75bn Lilly deal (2026) | Yes (Suzhou robotics lab) | Rentosertib Phase IIa |
| Recursion | Absorbed Exscientia; cut programmes 2025; released Boltz-2 | Yes (automated phenomics at scale) | Mixed; several programmes paused |
The diligence checklist falls straight out of the science. Does the platform generate proprietary wet-lab data at scale, the only durable grounding? Are there Phase II readouts, since Phase I success is now nearly uninformative about a platform's biology? Does it publish validity and uncertainty metrics against classical baselines, or only headline accuracy on favourable splits? And is the target de-risked independently of the chemistry, given that every high-profile failure of the era was a target failure, not a molecule failure?
Isomorphic is the instructive case: it runs no wet lab, which makes it the purest bet on the structure-prediction layer and the most exposed to its hallucination on novel targets. Its first human trials are the single most important forthcoming test of the no-wet-lab thesis.
Whether the tools can do the diligence
Less discussed, more immediate: the same generative tools an analyst uses to research a pipeline, a royalty asset, or a comparable deal hallucinate financial facts and citations exactly as they hallucinate mechanisms.
The reason is now reasonably well established: training regimes that penalise abstention statistically push models to guess confidently rather than admit ignorance. In a financial context that means confident numerical fabrication, more dangerous than a refusal because it is harder to detect.
The mitigations are the same ones the chemistry side discovered:
- Ground every claim in retrieval over primary sources (filings, dockets, peer-reviewed literature), not the model's parametric memory.
- Require citations and verify them; treat any confident number as unverified until checked against the source.
- Cross-check across more than one model.
- Keep a human as the final arbiter for any decision-bearing claim.
The discipline that makes a generative chemistry pipeline trustworthy is the discipline that makes a language model trustworthy for diligence: never act on the unaided, confident output.
What is solved, what is managed, what is not
It is worth ending on a clean partition, because the marketing blurs it and the science does not.
Managed (an engineering problem). Molecular-generation hallucination. Validity guarantees, cheap pre-synthesis filters, physical-validity checkers, and the design-make-test-analyse loop ensure the worst cases are caught cheaply and the rest in assays. The economics of enrichment rather than perfection are sound, and rentosertib is the proof.
Mitigated but unsolved (a reliability problem). Text-layer and novel-target hallucination. Retrieval, knowledge graphs, domain fine-tuning, and uncertainty quantification reduce confident fabrication without eliminating it, and they are weakest exactly where novelty is highest. Conformal guarantees erode under the distribution shift that defines genuine discovery, and the blind challenge showed newer AI does not automatically beat physics on the hardest tasks.
Untouched (a scientific problem). The biology. Whether a perfectly designed molecule against a chosen target actually treats a disease is a question AI has not answered, which is why AI-discovered drugs clear Phase I far above the norm and clear Phase II at roughly the norm. Catching molecular hallucination does not solve efficacy and safety.
The defensible conclusion, for a clinician or an investor, is neither boosterish nor dismissive. The hallucination problem at the design stage is real and largely contained by process rather than solved by models. The wet lab and the clinic remain the ultimate grounding mechanisms. Lilly's federated bet is the clearest sign that the industry understands the root cause to be data scarcity at the edge of the distribution, and is willing to spend a billion dollars to widen that edge. And the same tools, whether pointed at a molecule or a balance sheet, should be trusted only inside a verification-and-grounding workflow, never on their confident word alone.
All information in this report was accurate as of the research date and is derived from publicly available sources including peer-reviewed literature, preprints, regulatory guidance, company disclosures, and financial news reporting. Information may have changed since publication. This content is for informational purposes only and does not constitute investment, legal, medical, or financial advice. The author is not a lawyer, physician, or financial adviser.